Writing an Abstract for Your Research Paper

Definition and Purpose of Abstracts
An abstract is a short summary of your (published or unpublished) research paper, usually about a paragraph (c. 6-7 sentences, 150-250 words) long. A well-written abstract serves multiple purposes:
- an abstract lets readers get the gist or essence of your paper or article quickly, in order to decide whether to read the full paper;
- an abstract prepares readers to follow the detailed information, analyses, and arguments in your full paper;
- and, later, an abstract helps readers remember key points from your paper.
It’s also worth remembering that search engines and bibliographic databases use abstracts, as well as the title, to identify key terms for indexing your published paper. So what you include in your abstract and in your title are crucial for helping other researchers find your paper or article.
If you are writing an abstract for a course paper, your professor may give you specific guidelines for what to include and how to organize your abstract. Similarly, academic journals often have specific requirements for abstracts. So in addition to following the advice on this page, you should be sure to look for and follow any guidelines from the course or journal you’re writing for.
The Contents of an Abstract
Abstracts contain most of the following kinds of information in brief form. The body of your paper will, of course, develop and explain these ideas much more fully. As you will see in the samples below, the proportion of your abstract that you devote to each kind of information—and the sequence of that information—will vary, depending on the nature and genre of the paper that you are summarizing in your abstract. And in some cases, some of this information is implied, rather than stated explicitly. The Publication Manual of the American Psychological Association , which is widely used in the social sciences, gives specific guidelines for what to include in the abstract for different kinds of papers—for empirical studies, literature reviews or meta-analyses, theoretical papers, methodological papers, and case studies.
Here are the typical kinds of information found in most abstracts:
- the context or background information for your research; the general topic under study; the specific topic of your research
- the central questions or statement of the problem your research addresses
- what’s already known about this question, what previous research has done or shown
- the main reason(s) , the exigency, the rationale , the goals for your research—Why is it important to address these questions? Are you, for example, examining a new topic? Why is that topic worth examining? Are you filling a gap in previous research? Applying new methods to take a fresh look at existing ideas or data? Resolving a dispute within the literature in your field? . . .
- your research and/or analytical methods
- your main findings , results , or arguments
- the significance or implications of your findings or arguments.
Your abstract should be intelligible on its own, without a reader’s having to read your entire paper. And in an abstract, you usually do not cite references—most of your abstract will describe what you have studied in your research and what you have found and what you argue in your paper. In the body of your paper, you will cite the specific literature that informs your research.
When to Write Your Abstract
Although you might be tempted to write your abstract first because it will appear as the very first part of your paper, it’s a good idea to wait to write your abstract until after you’ve drafted your full paper, so that you know what you’re summarizing.
What follows are some sample abstracts in published papers or articles, all written by faculty at UW-Madison who come from a variety of disciplines. We have annotated these samples to help you see the work that these authors are doing within their abstracts.
Choosing Verb Tenses within Your Abstract
The social science sample (Sample 1) below uses the present tense to describe general facts and interpretations that have been and are currently true, including the prevailing explanation for the social phenomenon under study. That abstract also uses the present tense to describe the methods, the findings, the arguments, and the implications of the findings from their new research study. The authors use the past tense to describe previous research.
The humanities sample (Sample 2) below uses the past tense to describe completed events in the past (the texts created in the pulp fiction industry in the 1970s and 80s) and uses the present tense to describe what is happening in those texts, to explain the significance or meaning of those texts, and to describe the arguments presented in the article.
The science samples (Samples 3 and 4) below use the past tense to describe what previous research studies have done and the research the authors have conducted, the methods they have followed, and what they have found. In their rationale or justification for their research (what remains to be done), they use the present tense. They also use the present tense to introduce their study (in Sample 3, “Here we report . . .”) and to explain the significance of their study (In Sample 3, This reprogramming . . . “provides a scalable cell source for. . .”).
Sample Abstract 1
From the social sciences.
Reporting new findings about the reasons for increasing economic homogamy among spouses
Gonalons-Pons, Pilar, and Christine R. Schwartz. “Trends in Economic Homogamy: Changes in Assortative Mating or the Division of Labor in Marriage?” Demography , vol. 54, no. 3, 2017, pp. 985-1005.
![“The growing economic resemblance of spouses has contributed to rising inequality by increasing the number of couples in which there are two high- or two low-earning partners. [Annotation for the previous sentence: The first sentence introduces the topic under study (the “economic resemblance of spouses”). This sentence also implies the question underlying this research study: what are the various causes—and the interrelationships among them—for this trend?] The dominant explanation for this trend is increased assortative mating. Previous research has primarily relied on cross-sectional data and thus has been unable to disentangle changes in assortative mating from changes in the division of spouses’ paid labor—a potentially key mechanism given the dramatic rise in wives’ labor supply. [Annotation for the previous two sentences: These next two sentences explain what previous research has demonstrated. By pointing out the limitations in the methods that were used in previous studies, they also provide a rationale for new research.] We use data from the Panel Study of Income Dynamics (PSID) to decompose the increase in the correlation between spouses’ earnings and its contribution to inequality between 1970 and 2013 into parts due to (a) changes in assortative mating, and (b) changes in the division of paid labor. [Annotation for the previous sentence: The data, research and analytical methods used in this new study.] Contrary to what has often been assumed, the rise of economic homogamy and its contribution to inequality is largely attributable to changes in the division of paid labor rather than changes in sorting on earnings or earnings potential. Our findings indicate that the rise of economic homogamy cannot be explained by hypotheses centered on meeting and matching opportunities, and they show where in this process inequality is generated and where it is not.” (p. 985) [Annotation for the previous two sentences: The major findings from and implications and significance of this study.]](https://writing.wisc.edu/wp-content/uploads/sites/535/2019/08/Abstract-1.png "abstract of research article example")
Sample Abstract 2
From the humanities.
Analyzing underground pulp fiction publications in Tanzania, this article makes an argument about the cultural significance of those publications
Emily Callaci. “Street Textuality: Socialism, Masculinity, and Urban Belonging in Tanzania’s Pulp Fiction Publishing Industry, 1975-1985.” Comparative Studies in Society and History , vol. 59, no. 1, 2017, pp. 183-210.
![“From the mid-1970s through the mid-1980s, a network of young urban migrant men created an underground pulp fiction publishing industry in the city of Dar es Salaam. [Annotation for the previous sentence: The first sentence introduces the context for this research and announces the topic under study.] As texts that were produced in the underground economy of a city whose trajectory was increasingly charted outside of formalized planning and investment, these novellas reveal more than their narrative content alone. These texts were active components in the urban social worlds of the young men who produced them. They reveal a mode of urbanism otherwise obscured by narratives of decolonization, in which urban belonging was constituted less by national citizenship than by the construction of social networks, economic connections, and the crafting of reputations. This article argues that pulp fiction novellas of socialist era Dar es Salaam are artifacts of emergent forms of male sociability and mobility. In printing fictional stories about urban life on pilfered paper and ink, and distributing their texts through informal channels, these writers not only described urban communities, reputations, and networks, but also actually created them.” (p. 210) [Annotation for the previous sentences: The remaining sentences in this abstract interweave other essential information for an abstract for this article. The implied research questions: What do these texts mean? What is their historical and cultural significance, produced at this time, in this location, by these authors? The argument and the significance of this analysis in microcosm: these texts “reveal a mode or urbanism otherwise obscured . . .”; and “This article argues that pulp fiction novellas. . . .” This section also implies what previous historical research has obscured. And through the details in its argumentative claims, this section of the abstract implies the kinds of methods the author has used to interpret the novellas and the concepts under study (e.g., male sociability and mobility, urban communities, reputations, network. . . ).]](https://writing.wisc.edu/wp-content/uploads/sites/535/2019/08/Abstract-2.png "abstract of research article example")
Sample Abstract/Summary 3
From the sciences.
Reporting a new method for reprogramming adult mouse fibroblasts into induced cardiac progenitor cells
Lalit, Pratik A., Max R. Salick, Daryl O. Nelson, Jayne M. Squirrell, Christina M. Shafer, Neel G. Patel, Imaan Saeed, Eric G. Schmuck, Yogananda S. Markandeya, Rachel Wong, Martin R. Lea, Kevin W. Eliceiri, Timothy A. Hacker, Wendy C. Crone, Michael Kyba, Daniel J. Garry, Ron Stewart, James A. Thomson, Karen M. Downs, Gary E. Lyons, and Timothy J. Kamp. “Lineage Reprogramming of Fibroblasts into Proliferative Induced Cardiac Progenitor Cells by Defined Factors.” Cell Stem Cell , vol. 18, 2016, pp. 354-367.
![“Several studies have reported reprogramming of fibroblasts into induced cardiomyocytes; however, reprogramming into proliferative induced cardiac progenitor cells (iCPCs) remains to be accomplished. [Annotation for the previous sentence: The first sentence announces the topic under study, summarizes what’s already known or been accomplished in previous research, and signals the rationale and goals are for the new research and the problem that the new research solves: How can researchers reprogram fibroblasts into iCPCs?] Here we report that a combination of 11 or 5 cardiac factors along with canonical Wnt and JAK/STAT signaling reprogrammed adult mouse cardiac, lung, and tail tip fibroblasts into iCPCs. The iCPCs were cardiac mesoderm-restricted progenitors that could be expanded extensively while maintaining multipo-tency to differentiate into cardiomyocytes, smooth muscle cells, and endothelial cells in vitro. Moreover, iCPCs injected into the cardiac crescent of mouse embryos differentiated into cardiomyocytes. iCPCs transplanted into the post-myocardial infarction mouse heart improved survival and differentiated into cardiomyocytes, smooth muscle cells, and endothelial cells. [Annotation for the previous four sentences: The methods the researchers developed to achieve their goal and a description of the results.] Lineage reprogramming of adult somatic cells into iCPCs provides a scalable cell source for drug discovery, disease modeling, and cardiac regenerative therapy.” (p. 354) [Annotation for the previous sentence: The significance or implications—for drug discovery, disease modeling, and therapy—of this reprogramming of adult somatic cells into iCPCs.]](https://writing.wisc.edu/wp-content/uploads/sites/535/2019/08/Abstract-3.png "abstract of research article example")
Sample Abstract 4, a Structured Abstract
Reporting results about the effectiveness of antibiotic therapy in managing acute bacterial sinusitis, from a rigorously controlled study
Note: This journal requires authors to organize their abstract into four specific sections, with strict word limits. Because the headings for this structured abstract are self-explanatory, we have chosen not to add annotations to this sample abstract.
Wald, Ellen R., David Nash, and Jens Eickhoff. “Effectiveness of Amoxicillin/Clavulanate Potassium in the Treatment of Acute Bacterial Sinusitis in Children.” Pediatrics , vol. 124, no. 1, 2009, pp. 9-15.
“OBJECTIVE: The role of antibiotic therapy in managing acute bacterial sinusitis (ABS) in children is controversial. The purpose of this study was to determine the effectiveness of high-dose amoxicillin/potassium clavulanate in the treatment of children diagnosed with ABS.
METHODS : This was a randomized, double-blind, placebo-controlled study. Children 1 to 10 years of age with a clinical presentation compatible with ABS were eligible for participation. Patients were stratified according to age (<6 or ≥6 years) and clinical severity and randomly assigned to receive either amoxicillin (90 mg/kg) with potassium clavulanate (6.4 mg/kg) or placebo. A symptom survey was performed on days 0, 1, 2, 3, 5, 7, 10, 20, and 30. Patients were examined on day 14. Children’s conditions were rated as cured, improved, or failed according to scoring rules.
RESULTS: Two thousand one hundred thirty-five children with respiratory complaints were screened for enrollment; 139 (6.5%) had ABS. Fifty-eight patients were enrolled, and 56 were randomly assigned. The mean age was 6630 months. Fifty (89%) patients presented with persistent symptoms, and 6 (11%) presented with nonpersistent symptoms. In 24 (43%) children, the illness was classified as mild, whereas in the remaining 32 (57%) children it was severe. Of the 28 children who received the antibiotic, 14 (50%) were cured, 4 (14%) were improved, 4(14%) experienced treatment failure, and 6 (21%) withdrew. Of the 28children who received placebo, 4 (14%) were cured, 5 (18%) improved, and 19 (68%) experienced treatment failure. Children receiving the antibiotic were more likely to be cured (50% vs 14%) and less likely to have treatment failure (14% vs 68%) than children receiving the placebo.
CONCLUSIONS : ABS is a common complication of viral upper respiratory infections. Amoxicillin/potassium clavulanate results in significantly more cures and fewer failures than placebo, according to parental report of time to resolution.” (9)
Some Excellent Advice about Writing Abstracts for Basic Science Research Papers, by Professor Adriano Aguzzi from the Institute of Neuropathology at the University of Zurich:

Academic and Professional Writing
This is an accordion element with a series of buttons that open and close related content panels.
Analysis Papers
Reading Poetry
A Short Guide to Close Reading for Literary Analysis
Using Literary Quotations
Play Reviews
Writing a Rhetorical Précis to Analyze Nonfiction Texts
Incorporating Interview Data
Grant Proposals
Planning and Writing a Grant Proposal: The Basics
Additional Resources for Grants and Proposal Writing
Job Materials and Application Essays
Writing Personal Statements for Ph.D. Programs
- Before you begin: useful tips for writing your essay
- Guided brainstorming exercises
- Get more help with your essay
- Frequently Asked Questions
Resume Writing Tips
CV Writing Tips
Cover Letters
Business Letters
Proposals and Dissertations
Resources for Proposal Writers
Resources for Dissertators
Research Papers
Planning and Writing Research Papers
Quoting and Paraphrasing
Writing Annotated Bibliographies
Creating Poster Presentations
Thank-You Notes
Advice for Students Writing Thank-You Notes to Donors
Reading for a Review
Critical Reviews
Writing a Review of Literature
Scientific Reports
Scientific Report Format
Sample Lab Assignment
Writing for the Web
Writing an Effective Blog Post
Writing for Social Media: A Guide for Academics
- Features for Creative Writers
- Features for Work
- Features for Higher Education
- Features for Teachers
- Features for Non-Native Speakers
- Learn Blog Grammar Guide Community Events FAQ
- Grammar Guide
How to Write an Abstract (With Examples)

Sarah Oakley

Table of Contents
What is an abstract in a paper, how long should an abstract be, 5 steps for writing an abstract, examples of an abstract, how prowritingaid can help you write an abstract.
If you are writing a scientific research paper or a book proposal, you need to know how to write an abstract, which summarizes the contents of the paper or book.
When researchers are looking for peer-reviewed papers to use in their studies, the first place they will check is the abstract to see if it applies to their work. Therefore, your abstract is one of the most important parts of your entire paper.
In this article, we’ll explain what an abstract is, what it should include, and how to write one.
An abstract is a concise summary of the details within a report. Some abstracts give more details than others, but the main things you’ll be talking about are why you conducted the research, what you did, and what the results show.
When a reader is deciding whether to read your paper completely, they will first look at the abstract. You need to be concise in your abstract and give the reader the most important information so they can determine if they want to read the whole paper.
Remember that an abstract is the last thing you’ll want to write for the research paper because it directly references parts of the report. If you haven’t written the report, you won’t know what to include in your abstract.
If you are writing a paper for a journal or an assignment, the publication or academic institution might have specific formatting rules for how long your abstract should be. However, if they don’t, most abstracts are between 150 and 300 words long.
A short word count means your writing has to be precise and without filler words or phrases. Once you’ve written a first draft, you can always use an editing tool, such as ProWritingAid, to identify areas where you can reduce words and increase readability.
If your abstract is over the word limit, and you’ve edited it but still can’t figure out how to reduce it further, your abstract might include some things that aren’t needed. Here’s a list of three elements you can remove from your abstract:
Discussion : You don’t need to go into detail about the findings of your research because your reader will find your discussion within the paper.
Definition of terms : Your readers are interested the field you are writing about, so they are likely to understand the terms you are using. If not, they can always look them up. Your readers do not expect you to give a definition of terms in your abstract.
References and citations : You can mention there have been studies that support or have inspired your research, but you do not need to give details as the reader will find them in your bibliography.

Good writing = better grades
ProWritingAid will help you improve the style, strength, and clarity of all your assignments.
If you’ve never written an abstract before, and you’re wondering how to write an abstract, we’ve got some steps for you to follow. It’s best to start with planning your abstract, so we’ve outlined the details you need to include in your plan before you write.
Remember to consider your audience when you’re planning and writing your abstract. They are likely to skim read your abstract, so you want to be sure your abstract delivers all the information they’re expecting to see at key points.
1. What Should an Abstract Include?
Abstracts have a lot of information to cover in a short number of words, so it’s important to know what to include. There are three elements that need to be present in your abstract:
Your context is the background for where your research sits within your field of study. You should briefly mention any previous scientific papers or experiments that have led to your hypothesis and how research develops in those studies.
Your hypothesis is your prediction of what your study will show. As you are writing your abstract after you have conducted your research, you should still include your hypothesis in your abstract because it shows the motivation for your paper.
Throughout your abstract, you also need to include keywords and phrases that will help researchers to find your article in the databases they’re searching. Make sure the keywords are specific to your field of study and the subject you’re reporting on, otherwise your article might not reach the relevant audience.
2. Can You Use First Person in an Abstract?
You might think that first person is too informal for a research paper, but it’s not. Historically, writers of academic reports avoided writing in first person to uphold the formality standards of the time. However, first person is more accepted in research papers in modern times.
If you’re still unsure whether to write in first person for your abstract, refer to any style guide rules imposed by the journal you’re writing for or your teachers if you are writing an assignment.
3. Abstract Structure
Some scientific journals have strict rules on how to structure an abstract, so it’s best to check those first. If you don’t have any style rules to follow, try using the IMRaD structure, which stands for Introduction, Methodology, Results, and Discussion.

Following the IMRaD structure, start with an introduction. The amount of background information you should include depends on your specific research area. Adding a broad overview gives you less room to include other details. Remember to include your hypothesis in this section.
The next part of your abstract should cover your methodology. Try to include the following details if they apply to your study:
What type of research was conducted?
How were the test subjects sampled?
What were the sample sizes?
What was done to each group?
How long was the experiment?
How was data recorded and interpreted?
Following the methodology, include a sentence or two about the results, which is where your reader will determine if your research supports or contradicts their own investigations.
The results are also where most people will want to find out what your outcomes were, even if they are just mildly interested in your research area. You should be specific about all the details but as concise as possible.
The last few sentences are your conclusion. It needs to explain how your findings affect the context and whether your hypothesis was correct. Include the primary take-home message, additional findings of importance, and perspective. Also explain whether there is scope for further research into the subject of your report.
Your conclusion should be honest and give the reader the ultimate message that your research shows. Readers trust the conclusion, so make sure you’re not fabricating the results of your research. Some readers won’t read your entire paper, but this section will tell them if it’s worth them referencing it in their own study.
4. How to Start an Abstract
The first line of your abstract should give your reader the context of your report by providing background information. You can use this sentence to imply the motivation for your research.
You don’t need to use a hook phrase or device in your first sentence to grab the reader’s attention. Your reader will look to establish relevance quickly, so readability and clarity are more important than trying to persuade the reader to read on.
5. How to Format an Abstract
Most abstracts use the same formatting rules, which help the reader identify the abstract so they know where to look for it.
Here’s a list of formatting guidelines for writing an abstract:
Stick to one paragraph
Use block formatting with no indentation at the beginning
Put your abstract straight after the title and acknowledgements pages
Use present or past tense, not future tense
There are two primary types of abstract you could write for your paper—descriptive and informative.
An informative abstract is the most common, and they follow the structure mentioned previously. They are longer than descriptive abstracts because they cover more details.
Descriptive abstracts differ from informative abstracts, as they don’t include as much discussion or detail. The word count for a descriptive abstract is between 50 and 150 words.
Here is an example of an informative abstract:
A growing trend exists for authors to employ a more informal writing style that uses “we” in academic writing to acknowledge one’s stance and engagement. However, few studies have compared the ways in which the first-person pronoun “we” is used in the abstracts and conclusions of empirical papers. To address this lacuna in the literature, this study conducted a systematic corpus analysis of the use of “we” in the abstracts and conclusions of 400 articles collected from eight leading electrical and electronic (EE) engineering journals. The abstracts and conclusions were extracted to form two subcorpora, and an integrated framework was applied to analyze and seek to explain how we-clusters and we-collocations were employed. Results revealed whether authors’ use of first-person pronouns partially depends on a journal policy. The trend of using “we” showed that a yearly increase occurred in the frequency of “we” in EE journal papers, as well as the existence of three “we-use” types in the article conclusions and abstracts: exclusive, inclusive, and ambiguous. Other possible “we-use” alternatives such as “I” and other personal pronouns were used very rarely—if at all—in either section. These findings also suggest that the present tense was used more in article abstracts, but the present perfect tense was the most preferred tense in article conclusions. Both research and pedagogical implications are proffered and critically discussed.
Wang, S., Tseng, W.-T., & Johanson, R. (2021). To We or Not to We: Corpus-Based Research on First-Person Pronoun Use in Abstracts and Conclusions. SAGE Open, 11(2).
Here is an example of a descriptive abstract:
From the 1850s to the present, considerable criminological attention has focused on the development of theoretically-significant systems for classifying crime. This article reviews and attempts to evaluate a number of these efforts, and we conclude that further work on this basic task is needed. The latter part of the article explicates a conceptual foundation for a crime pattern classification system, and offers a preliminary taxonomy of crime.
Farr, K. A., & Gibbons, D. C. (1990). Observations on the Development of Crime Categories. International Journal of Offender Therapy and Comparative Criminology, 34(3), 223–237.
If you want to ensure your abstract is grammatically correct and easy to read, you can use ProWritingAid to edit it. The software integrates with Microsoft Word, Google Docs, and most web browsers, so you can make the most of it wherever you’re writing your paper.

Before you edit with ProWritingAid, make sure the suggestions you are seeing are relevant for your document by changing the document type to “Abstract” within the Academic writing style section.
You can use the Readability report to check your abstract for places to improve the clarity of your writing. Some suggestions might show you where to remove words, which is great if you’re over your word count.
We hope the five steps and examples we’ve provided help you write a great abstract for your research paper.
Get started with ProWritingAid
Drop us a line or let's stay in touch via :

What this handout is about
This handout provides definitions and examples of the two main types of abstracts: descriptive and informative. It also provides guidelines for constructing an abstract and general tips for you to keep in mind when drafting. Finally, it includes a few examples of abstracts broken down into their component parts.
What is an abstract?
An abstract is a self-contained, short, and powerful statement that describes a larger work. Components vary according to discipline. An abstract of a social science or scientific work may contain the scope, purpose, results, and contents of the work. An abstract of a humanities work may contain the thesis, background, and conclusion of the larger work. An abstract is not a review, nor does it evaluate the work being abstracted. While it contains key words found in the larger work, the abstract is an original document rather than an excerpted passage.
Why write an abstract?
You may write an abstract for various reasons. The two most important are selection and indexing. Abstracts allow readers who may be interested in a longer work to quickly decide whether it is worth their time to read it. Also, many online databases use abstracts to index larger works. Therefore, abstracts should contain keywords and phrases that allow for easy searching.
Say you are beginning a research project on how Brazilian newspapers helped Brazil’s ultra-liberal president Luiz Ignácio da Silva wrest power from the traditional, conservative power base. A good first place to start your research is to search Dissertation Abstracts International for all dissertations that deal with the interaction between newspapers and politics. “Newspapers and politics” returned 569 hits. A more selective search of “newspapers and Brazil” returned 22 hits. That is still a fair number of dissertations. Titles can sometimes help winnow the field, but many titles are not very descriptive. For example, one dissertation is titled “Rhetoric and Riot in Rio de Janeiro.” It is unclear from the title what this dissertation has to do with newspapers in Brazil. One option would be to download or order the entire dissertation on the chance that it might speak specifically to the topic. A better option is to read the abstract. In this case, the abstract reveals the main focus of the dissertation:
This dissertation examines the role of newspaper editors in the political turmoil and strife that characterized late First Empire Rio de Janeiro (1827-1831). Newspaper editors and their journals helped change the political culture of late First Empire Rio de Janeiro by involving the people in the discussion of state. This change in political culture is apparent in Emperor Pedro I’s gradual loss of control over the mechanisms of power. As the newspapers became more numerous and powerful, the Emperor lost his legitimacy in the eyes of the people. To explore the role of the newspapers in the political events of the late First Empire, this dissertation analyzes all available newspapers published in Rio de Janeiro from 1827 to 1831. Newspapers and their editors were leading forces in the effort to remove power from the hands of the ruling elite and place it under the control of the people. In the process, newspapers helped change how politics operated in the constitutional monarchy of Brazil.
From this abstract you now know that although the dissertation has nothing to do with modern Brazilian politics, it does cover the role of newspapers in changing traditional mechanisms of power. After reading the abstract, you can make an informed judgment about whether the dissertation would be worthwhile to read.
Besides selection, the other main purpose of the abstract is for indexing. Most article databases in the online catalog of the library enable you to search abstracts. This allows for quick retrieval by users and limits the extraneous items recalled by a “full-text” search. However, for an abstract to be useful in an online retrieval system, it must incorporate the key terms that a potential researcher would use to search. For example, if you search Dissertation Abstracts International using the keywords “France” “revolution” and “politics,” the search engine would search through all the abstracts in the database that included those three words. Without an abstract, the search engine would be forced to search titles, which, as we have seen, may not be fruitful, or else search the full text. It’s likely that a lot more than 60 dissertations have been written with those three words somewhere in the body of the entire work. By incorporating keywords into the abstract, the author emphasizes the central topics of the work and gives prospective readers enough information to make an informed judgment about the applicability of the work.
When do people write abstracts?
- when submitting articles to journals, especially online journals
- when applying for research grants
- when writing a book proposal
- when completing the Ph.D. dissertation or M.A. thesis
- when writing a proposal for a conference paper
- when writing a proposal for a book chapter
Most often, the author of the entire work (or prospective work) writes the abstract. However, there are professional abstracting services that hire writers to draft abstracts of other people’s work. In a work with multiple authors, the first author usually writes the abstract. Undergraduates are sometimes asked to draft abstracts of books/articles for classmates who have not read the larger work.
Types of abstracts
There are two types of abstracts: descriptive and informative. They have different aims, so as a consequence they have different components and styles. There is also a third type called critical, but it is rarely used. If you want to find out more about writing a critique or a review of a work, see the UNC Writing Center handout on writing a literature review . If you are unsure which type of abstract you should write, ask your instructor (if the abstract is for a class) or read other abstracts in your field or in the journal where you are submitting your article.
Descriptive abstracts
A descriptive abstract indicates the type of information found in the work. It makes no judgments about the work, nor does it provide results or conclusions of the research. It does incorporate key words found in the text and may include the purpose, methods, and scope of the research. Essentially, the descriptive abstract describes the work being abstracted. Some people consider it an outline of the work, rather than a summary. Descriptive abstracts are usually very short—100 words or less.
Informative abstracts
The majority of abstracts are informative. While they still do not critique or evaluate a work, they do more than describe it. A good informative abstract acts as a surrogate for the work itself. That is, the writer presents and explains all the main arguments and the important results and evidence in the complete article/paper/book. An informative abstract includes the information that can be found in a descriptive abstract (purpose, methods, scope) but also includes the results and conclusions of the research and the recommendations of the author. The length varies according to discipline, but an informative abstract is rarely more than 10% of the length of the entire work. In the case of a longer work, it may be much less.
Here are examples of a descriptive and an informative abstract of this handout on abstracts . Descriptive abstract:
The two most common abstract types—descriptive and informative—are described and examples of each are provided.
Informative abstract:
Abstracts present the essential elements of a longer work in a short and powerful statement. The purpose of an abstract is to provide prospective readers the opportunity to judge the relevance of the longer work to their projects. Abstracts also include the key terms found in the longer work and the purpose and methods of the research. Authors abstract various longer works, including book proposals, dissertations, and online journal articles. There are two main types of abstracts: descriptive and informative. A descriptive abstract briefly describes the longer work, while an informative abstract presents all the main arguments and important results. This handout provides examples of various types of abstracts and instructions on how to construct one.
Which type should I use?
Your best bet in this case is to ask your instructor or refer to the instructions provided by the publisher. You can also make a guess based on the length allowed; i.e., 100-120 words = descriptive; 250+ words = informative.
How do I write an abstract?
The format of your abstract will depend on the work being abstracted. An abstract of a scientific research paper will contain elements not found in an abstract of a literature article, and vice versa. However, all abstracts share several mandatory components, and there are also some optional parts that you can decide to include or not. When preparing to draft your abstract, keep the following key process elements in mind:
- Reason for writing: What is the importance of the research? Why would a reader be interested in the larger work?
- Problem: What problem does this work attempt to solve? What is the scope of the project? What is the main argument/thesis/claim?
- Methodology: An abstract of a scientific work may include specific models or approaches used in the larger study. Other abstracts may describe the types of evidence used in the research.
- Results: Again, an abstract of a scientific work may include specific data that indicates the results of the project. Other abstracts may discuss the findings in a more general way.
- Implications: What changes should be implemented as a result of the findings of the work? How does this work add to the body of knowledge on the topic?
(This list of elements is adapted with permission from Philip Koopman, “How to Write an Abstract.” )
All abstracts include:
- A full citation of the source, preceding the abstract.
- The most important information first.
- The same type and style of language found in the original, including technical language.
- Key words and phrases that quickly identify the content and focus of the work.
- Clear, concise, and powerful language.
Abstracts may include:
- The thesis of the work, usually in the first sentence.
- Background information that places the work in the larger body of literature.
- The same chronological structure as the original work.
How not to write an abstract:
- Do not refer extensively to other works.
- Do not add information not contained in the original work.
- Do not define terms.
If you are abstracting your own writing
When abstracting your own work, it may be difficult to condense a piece of writing that you have agonized over for weeks (or months, or even years) into a 250-word statement. There are some tricks that you could use to make it easier, however.
Reverse outlining:
This technique is commonly used when you are having trouble organizing your own writing. The process involves writing down the main idea of each paragraph on a separate piece of paper– see our short video . For the purposes of writing an abstract, try grouping the main ideas of each section of the paper into a single sentence. Practice grouping ideas using webbing or color coding .
For a scientific paper, you may have sections titled Purpose, Methods, Results, and Discussion. Each one of these sections will be longer than one paragraph, but each is grouped around a central idea. Use reverse outlining to discover the central idea in each section and then distill these ideas into one statement.
Cut and paste:
To create a first draft of an abstract of your own work, you can read through the entire paper and cut and paste sentences that capture key passages. This technique is useful for social science research with findings that cannot be encapsulated by neat numbers or concrete results. A well-written humanities draft will have a clear and direct thesis statement and informative topic sentences for paragraphs or sections. Isolate these sentences in a separate document and work on revising them into a unified paragraph.
If you are abstracting someone else’s writing
When abstracting something you have not written, you cannot summarize key ideas just by cutting and pasting. Instead, you must determine what a prospective reader would want to know about the work. There are a few techniques that will help you in this process:
Identify key terms:
Search through the entire document for key terms that identify the purpose, scope, and methods of the work. Pay close attention to the Introduction (or Purpose) and the Conclusion (or Discussion). These sections should contain all the main ideas and key terms in the paper. When writing the abstract, be sure to incorporate the key terms.
Highlight key phrases and sentences:
Instead of cutting and pasting the actual words, try highlighting sentences or phrases that appear to be central to the work. Then, in a separate document, rewrite the sentences and phrases in your own words.
Don’t look back:
After reading the entire work, put it aside and write a paragraph about the work without referring to it. In the first draft, you may not remember all the key terms or the results, but you will remember what the main point of the work was. Remember not to include any information you did not get from the work being abstracted.
Revise, revise, revise
No matter what type of abstract you are writing, or whether you are abstracting your own work or someone else’s, the most important step in writing an abstract is to revise early and often. When revising, delete all extraneous words and incorporate meaningful and powerful words. The idea is to be as clear and complete as possible in the shortest possible amount of space. The Word Count feature of Microsoft Word can help you keep track of how long your abstract is and help you hit your target length.
Example 1: Humanities abstract
Kenneth Tait Andrews, “‘Freedom is a constant struggle’: The dynamics and consequences of the Mississippi Civil Rights Movement, 1960-1984” Ph.D. State University of New York at Stony Brook, 1997 DAI-A 59/02, p. 620, Aug 1998
This dissertation examines the impacts of social movements through a multi-layered study of the Mississippi Civil Rights Movement from its peak in the early 1960s through the early 1980s. By examining this historically important case, I clarify the process by which movements transform social structures and the constraints movements face when they try to do so. The time period studied includes the expansion of voting rights and gains in black political power, the desegregation of public schools and the emergence of white-flight academies, and the rise and fall of federal anti-poverty programs. I use two major research strategies: (1) a quantitative analysis of county-level data and (2) three case studies. Data have been collected from archives, interviews, newspapers, and published reports. This dissertation challenges the argument that movements are inconsequential. Some view federal agencies, courts, political parties, or economic elites as the agents driving institutional change, but typically these groups acted in response to the leverage brought to bear by the civil rights movement. The Mississippi movement attempted to forge independent structures for sustaining challenges to local inequities and injustices. By propelling change in an array of local institutions, movement infrastructures had an enduring legacy in Mississippi.
Now let’s break down this abstract into its component parts to see how the author has distilled his entire dissertation into a ~200 word abstract.
What the dissertation does This dissertation examines the impacts of social movements through a multi-layered study of the Mississippi Civil Rights Movement from its peak in the early 1960s through the early 1980s. By examining this historically important case, I clarify the process by which movements transform social structures and the constraints movements face when they try to do so.
How the dissertation does it The time period studied in this dissertation includes the expansion of voting rights and gains in black political power, the desegregation of public schools and the emergence of white-flight academies, and the rise and fall of federal anti-poverty programs. I use two major research strategies: (1) a quantitative analysis of county-level data and (2) three case studies.
What materials are used Data have been collected from archives, interviews, newspapers, and published reports.
Conclusion This dissertation challenges the argument that movements are inconsequential. Some view federal agencies, courts, political parties, or economic elites as the agents driving institutional change, but typically these groups acted in response to movement demands and the leverage brought to bear by the civil rights movement. The Mississippi movement attempted to forge independent structures for sustaining challenges to local inequities and injustices. By propelling change in an array of local institutions, movement infrastructures had an enduring legacy in Mississippi.
Keywords social movements Civil Rights Movement Mississippi voting rights desegregation
Example 2: Science Abstract
Luis Lehner, “Gravitational radiation from black hole spacetimes” Ph.D. University of Pittsburgh, 1998 DAI-B 59/06, p. 2797, Dec 1998
The problem of detecting gravitational radiation is receiving considerable attention with the construction of new detectors in the United States, Europe, and Japan. The theoretical modeling of the wave forms that would be produced in particular systems will expedite the search for and analysis of detected signals. The characteristic formulation of GR is implemented to obtain an algorithm capable of evolving black holes in 3D asymptotically flat spacetimes. Using compactification techniques, future null infinity is included in the evolved region, which enables the unambiguous calculation of the radiation produced by some compact source. A module to calculate the waveforms is constructed and included in the evolution algorithm. This code is shown to be second-order convergent and to handle highly non-linear spacetimes. In particular, we have shown that the code can handle spacetimes whose radiation is equivalent to a galaxy converting its whole mass into gravitational radiation in one second. We further use the characteristic formulation to treat the region close to the singularity in black hole spacetimes. The code carefully excises a region surrounding the singularity and accurately evolves generic black hole spacetimes with apparently unlimited stability.
This science abstract covers much of the same ground as the humanities one, but it asks slightly different questions.
Why do this study The problem of detecting gravitational radiation is receiving considerable attention with the construction of new detectors in the United States, Europe, and Japan. The theoretical modeling of the wave forms that would be produced in particular systems will expedite the search and analysis of the detected signals.
What the study does The characteristic formulation of GR is implemented to obtain an algorithm capable of evolving black holes in 3D asymptotically flat spacetimes. Using compactification techniques, future null infinity is included in the evolved region, which enables the unambiguous calculation of the radiation produced by some compact source. A module to calculate the waveforms is constructed and included in the evolution algorithm.
Results This code is shown to be second-order convergent and to handle highly non-linear spacetimes. In particular, we have shown that the code can handle spacetimes whose radiation is equivalent to a galaxy converting its whole mass into gravitational radiation in one second. We further use the characteristic formulation to treat the region close to the singularity in black hole spacetimes. The code carefully excises a region surrounding the singularity and accurately evolves generic black hole spacetimes with apparently unlimited stability.
Keywords gravitational radiation (GR) spacetimes black holes
Works consulted
We consulted these works while writing this handout. This is not a comprehensive list of resources on the handout’s topic, and we encourage you to do your own research to find additional publications. Please do not use this list as a model for the format of your own reference list, as it may not match the citation style you are using. For guidance on formatting citations, please see the UNC Libraries citation tutorial . We revise these tips periodically and welcome feedback.
Belcher, Wendy Laura. 2009. Writing Your Journal Article in Twelve Weeks: A Guide to Academic Publishing Success. Thousand Oaks, CA: Sage Press.
Koopman, Philip. 1997. “How to Write an Abstract.” Carnegie Mellon University. October 1997. http://users.ece.cmu.edu/~koopman/essays/abstract.html .
Lancaster, F.W. 2003. Indexing And Abstracting in Theory and Practice , 3rd ed. London: Facet Publishing.
You may reproduce it for non-commercial use if you use the entire handout and attribute the source: The Writing Center, University of North Carolina at Chapel Hill
Make a Gift
- Privacy Policy
Home » Research Paper Abstract – Writing Guide and Examples
Research Paper Abstract – Writing Guide and Examples
Table of Contents

Research Paper Abstract
Research Paper Abstract is a brief summary of a research pape r that describes the study’s purpose, methods, findings, and conclusions . It is often the first section of the paper that readers encounter, and its purpose is to provide a concise and accurate overview of the paper’s content. The typical length of an abstract is usually around 150-250 words, and it should be written in a concise and clear manner.
Research Paper Abstract Structure
The structure of a research paper abstract usually includes the following elements:
- Background or Introduction: Briefly describe the problem or research question that the study addresses.
- Methods : Explain the methodology used to conduct the study, including the participants, materials, and procedures.
- Results : Summarize the main findings of the study, including statistical analyses and key outcomes.
- Conclusions : Discuss the implications of the study’s findings and their significance for the field, as well as any limitations or future directions for research.
- Keywords : List a few keywords that describe the main topics or themes of the research.
How to Write Research Paper Abstract
Here are the steps to follow when writing a research paper abstract:
- Start by reading your paper: Before you write an abstract, you should have a complete understanding of your paper. Read through the paper carefully, making sure you understand the purpose, methods, results, and conclusions.
- Identify the key components : Identify the key components of your paper, such as the research question, methods used, results obtained, and conclusion reached.
- Write a draft: Write a draft of your abstract, using concise and clear language. Make sure to include all the important information, but keep it short and to the point. A good rule of thumb is to keep your abstract between 150-250 words.
- Use clear and concise language : Use clear and concise language to explain the purpose of your study, the methods used, the results obtained, and the conclusions drawn.
- Emphasize your findings: Emphasize your findings in the abstract, highlighting the key results and the significance of your study.
- Revise and edit: Once you have a draft, revise and edit it to ensure that it is clear, concise, and free from errors.
- Check the formatting: Finally, check the formatting of your abstract to make sure it meets the requirements of the journal or conference where you plan to submit it.
Research Paper Abstract Examples
Research Paper Abstract Examples could be following:
Title : “The Effectiveness of Cognitive-Behavioral Therapy for Treating Anxiety Disorders: A Meta-Analysis”
Abstract : This meta-analysis examines the effectiveness of cognitive-behavioral therapy (CBT) in treating anxiety disorders. Through the analysis of 20 randomized controlled trials, we found that CBT is a highly effective treatment for anxiety disorders, with large effect sizes across a range of anxiety disorders, including generalized anxiety disorder, panic disorder, and social anxiety disorder. Our findings support the use of CBT as a first-line treatment for anxiety disorders and highlight the importance of further research to identify the mechanisms underlying its effectiveness.
Title : “Exploring the Role of Parental Involvement in Children’s Education: A Qualitative Study”
Abstract : This qualitative study explores the role of parental involvement in children’s education. Through in-depth interviews with 20 parents of children in elementary school, we found that parental involvement takes many forms, including volunteering in the classroom, helping with homework, and communicating with teachers. We also found that parental involvement is influenced by a range of factors, including parent and child characteristics, school culture, and socio-economic status. Our findings suggest that schools and educators should prioritize building strong partnerships with parents to support children’s academic success.
Title : “The Impact of Exercise on Cognitive Function in Older Adults: A Systematic Review and Meta-Analysis”
Abstract : This paper presents a systematic review and meta-analysis of the existing literature on the impact of exercise on cognitive function in older adults. Through the analysis of 25 randomized controlled trials, we found that exercise is associated with significant improvements in cognitive function, particularly in the domains of executive function and attention. Our findings highlight the potential of exercise as a non-pharmacological intervention to support cognitive health in older adults.
When to Write Research Paper Abstract
The abstract of a research paper should typically be written after you have completed the main body of the paper. This is because the abstract is intended to provide a brief summary of the key points and findings of the research, and you can’t do that until you have completed the research and written about it in detail.
Once you have completed your research paper, you can begin writing your abstract. It is important to remember that the abstract should be a concise summary of your research paper, and should be written in a way that is easy to understand for readers who may not have expertise in your specific area of research.
Purpose of Research Paper Abstract
The purpose of a research paper abstract is to provide a concise summary of the key points and findings of a research paper. It is typically a brief paragraph or two that appears at the beginning of the paper, before the introduction, and is intended to give readers a quick overview of the paper’s content.
The abstract should include a brief statement of the research problem, the methods used to investigate the problem, the key results and findings, and the main conclusions and implications of the research. It should be written in a clear and concise manner, avoiding jargon and technical language, and should be understandable to a broad audience.
The abstract serves as a way to quickly and easily communicate the main points of a research paper to potential readers, such as academics, researchers, and students, who may be looking for information on a particular topic. It can also help researchers determine whether a paper is relevant to their own research interests and whether they should read the full paper.
About the author

Muhammad Hassan
Researcher, Academic Writer, Web developer
You may also like

How to Cite Research Paper – All Formats and...

Delimitations in Research – Types, Examples and...

Research Paper Format – Types, Examples and...

Research Design – Types, Methods and Examples

Research Paper Title – Writing Guide and Example

Research Paper Introduction – Writing Guide and...
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, automatically generate references for free.
- Knowledge Base
- Dissertation
- How to Write an Abstract | Steps & Examples
How to Write an Abstract | Steps & Examples
Published on 1 March 2019 by Shona McCombes . Revised on 10 October 2022 by Eoghan Ryan.
An abstract is a short summary of a longer work (such as a dissertation or research paper ). The abstract concisely reports the aims and outcomes of your research, so that readers know exactly what your paper is about.
Although the structure may vary slightly depending on your discipline, your abstract should describe the purpose of your work, the methods you’ve used, and the conclusions you’ve drawn.
One common way to structure your abstract is to use the IMRaD structure. This stands for:
- Introduction
Abstracts are usually around 100–300 words, but there’s often a strict word limit, so make sure to check the relevant requirements.
In a dissertation or thesis , include the abstract on a separate page, after the title page and acknowledgements but before the table of contents .
Instantly correct all language mistakes in your text
Be assured that you'll submit flawless writing. Upload your document to correct all your mistakes.

Table of contents
Abstract example, when to write an abstract, step 1: introduction, step 2: methods, step 3: results, step 4: discussion, tips for writing an abstract, frequently asked questions about abstracts.
Hover over the different parts of the abstract to see how it is constructed.
This paper examines the role of silent movies as a mode of shared experience in the UK during the early twentieth century. At this time, high immigration rates resulted in a significant percentage of non-English-speaking citizens. These immigrants faced numerous economic and social obstacles, including exclusion from public entertainment and modes of discourse (newspapers, theater, radio).
Incorporating evidence from reviews, personal correspondence, and diaries, this study demonstrates that silent films were an affordable and inclusive source of entertainment. It argues for the accessible economic and representational nature of early cinema. These concerns are particularly evident in the low price of admission and in the democratic nature of the actors’ exaggerated gestures, which allowed the plots and action to be easily grasped by a diverse audience despite language barriers.
Keywords: silent movies, immigration, public discourse, entertainment, early cinema, language barriers.
The only proofreading tool specialized in correcting academic writing
The academic proofreading tool has been trained on 1000s of academic texts and by native English editors. Making it the most accurate and reliable proofreading tool for students.

Correct my document today
You will almost always have to include an abstract when:
- Completing a thesis or dissertation
- Submitting a research paper to an academic journal
- Writing a book proposal
- Applying for research grants
It’s easiest to write your abstract last, because it’s a summary of the work you’ve already done. Your abstract should:
- Be a self-contained text, not an excerpt from your paper
- Be fully understandable on its own
- Reflect the structure of your larger work
Start by clearly defining the purpose of your research. What practical or theoretical problem does the research respond to, or what research question did you aim to answer?
You can include some brief context on the social or academic relevance of your topic, but don’t go into detailed background information. If your abstract uses specialised terms that would be unfamiliar to the average academic reader or that have various different meanings, give a concise definition.
After identifying the problem, state the objective of your research. Use verbs like “investigate,” “test,” “analyse,” or “evaluate” to describe exactly what you set out to do.
This part of the abstract can be written in the present or past simple tense but should never refer to the future, as the research is already complete.
- This study will investigate the relationship between coffee consumption and productivity.
- This study investigates the relationship between coffee consumption and productivity.
Next, indicate the research methods that you used to answer your question. This part should be a straightforward description of what you did in one or two sentences. It is usually written in the past simple tense, as it refers to completed actions.
- Structured interviews will be conducted with 25 participants.
- Structured interviews were conducted with 25 participants.
Don’t evaluate validity or obstacles here — the goal is not to give an account of the methodology’s strengths and weaknesses, but to give the reader a quick insight into the overall approach and procedures you used.
Next, summarise the main research results . This part of the abstract can be in the present or past simple tense.
- Our analysis has shown a strong correlation between coffee consumption and productivity.
- Our analysis shows a strong correlation between coffee consumption and productivity.
- Our analysis showed a strong correlation between coffee consumption and productivity.
Depending on how long and complex your research is, you may not be able to include all results here. Try to highlight only the most important findings that will allow the reader to understand your conclusions.
Finally, you should discuss the main conclusions of your research : what is your answer to the problem or question? The reader should finish with a clear understanding of the central point that your research has proved or argued. Conclusions are usually written in the present simple tense.
- We concluded that coffee consumption increases productivity.
- We conclude that coffee consumption increases productivity.
If there are important limitations to your research (for example, related to your sample size or methods), you should mention them briefly in the abstract. This allows the reader to accurately assess the credibility and generalisability of your research.
If your aim was to solve a practical problem, your discussion might include recommendations for implementation. If relevant, you can briefly make suggestions for further research.
If your paper will be published, you might have to add a list of keywords at the end of the abstract. These keywords should reference the most important elements of the research to help potential readers find your paper during their own literature searches.
Be aware that some publication manuals, such as APA Style , have specific formatting requirements for these keywords.
It can be a real challenge to condense your whole work into just a couple of hundred words, but the abstract will be the first (and sometimes only) part that people read, so it’s important to get it right. These strategies can help you get started.
Read other abstracts
The best way to learn the conventions of writing an abstract in your discipline is to read other people’s. You probably already read lots of journal article abstracts while conducting your literature review —try using them as a framework for structure and style.
You can also find lots of dissertation abstract examples in thesis and dissertation databases .
Reverse outline
Not all abstracts will contain precisely the same elements. For longer works, you can write your abstract through a process of reverse outlining.
For each chapter or section, list keywords and draft one to two sentences that summarise the central point or argument. This will give you a framework of your abstract’s structure. Next, revise the sentences to make connections and show how the argument develops.
Write clearly and concisely
A good abstract is short but impactful, so make sure every word counts. Each sentence should clearly communicate one main point.
To keep your abstract or summary short and clear:
- Avoid passive sentences: Passive constructions are often unnecessarily long. You can easily make them shorter and clearer by using the active voice.
- Avoid long sentences: Substitute longer expressions for concise expressions or single words (e.g., “In order to” for “To”).
- Avoid obscure jargon: The abstract should be understandable to readers who are not familiar with your topic.
- Avoid repetition and filler words: Replace nouns with pronouns when possible and eliminate unnecessary words.
- Avoid detailed descriptions: An abstract is not expected to provide detailed definitions, background information, or discussions of other scholars’ work. Instead, include this information in the body of your thesis or paper.
If you’re struggling to edit down to the required length, you can get help from expert editors with Scribbr’s professional proofreading services .
Check your formatting
If you are writing a thesis or dissertation or submitting to a journal, there are often specific formatting requirements for the abstract—make sure to check the guidelines and format your work correctly. For APA research papers you can follow the APA abstract format .
Checklist: Abstract
The word count is within the required length, or a maximum of one page.
The abstract appears after the title page and acknowledgements and before the table of contents .
I have clearly stated my research problem and objectives.
I have briefly described my methodology .
I have summarized the most important results .
I have stated my main conclusions .
I have mentioned any important limitations and recommendations.
The abstract can be understood by someone without prior knowledge of the topic.
You've written a great abstract! Use the other checklists to continue improving your thesis or dissertation.
An abstract is a concise summary of an academic text (such as a journal article or dissertation ). It serves two main purposes:
- To help potential readers determine the relevance of your paper for their own research.
- To communicate your key findings to those who don’t have time to read the whole paper.
Abstracts are often indexed along with keywords on academic databases, so they make your work more easily findable. Since the abstract is the first thing any reader sees, it’s important that it clearly and accurately summarises the contents of your paper.
An abstract for a thesis or dissertation is usually around 150–300 words. There’s often a strict word limit, so make sure to check your university’s requirements.
The abstract is the very last thing you write. You should only write it after your research is complete, so that you can accurately summarize the entirety of your thesis or paper.
Avoid citing sources in your abstract . There are two reasons for this:
- The abstract should focus on your original research, not on the work of others.
- The abstract should be self-contained and fully understandable without reference to other sources.
There are some circumstances where you might need to mention other sources in an abstract: for example, if your research responds directly to another study or focuses on the work of a single theorist. In general, though, don’t include citations unless absolutely necessary.
The abstract appears on its own page, after the title page and acknowledgements but before the table of contents .
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the ‘Cite this Scribbr article’ button to automatically add the citation to our free Reference Generator.
McCombes, S. (2022, October 10). How to Write an Abstract | Steps & Examples. Scribbr. Retrieved 26 May 2024, from https://www.scribbr.co.uk/thesis-dissertation/abstract/
Is this article helpful?

Shona McCombes
Other students also liked, how to write a thesis or dissertation introduction, thesis & dissertation acknowledgements | tips & examples, dissertation title page.
- Affiliate Program

- UNITED STATES
- 台灣 (TAIWAN)
- TÜRKIYE (TURKEY)
- Academic Editing Services
- - Research Paper
- - Journal Manuscript
- - Dissertation
- - College & University Assignments
- Admissions Editing Services
- - Application Essay
- - Personal Statement
- - Recommendation Letter
- - Cover Letter
- - CV/Resume
- Business Editing Services
- - Business Documents
- - Report & Brochure
- - Website & Blog
- Writer Editing Services
- - Script & Screenplay
- Our Editors
- Client Reviews
- Editing & Proofreading Prices
- Wordvice Points
- Partner Discount
- Plagiarism Checker
- APA Citation Generator
- MLA Citation Generator
- Chicago Citation Generator
- Vancouver Citation Generator
- - APA Style
- - MLA Style
- - Chicago Style
- - Vancouver Style
- Writing & Editing Guide
- Academic Resources
- Admissions Resources
How to Write an Abstract for a Research Paper | Examples
What is a research paper abstract?
Research paper abstracts summarize your study quickly and succinctly to journal editors and researchers and prompt them to read further. But with the ubiquity of online publication databases, writing a compelling abstract is even more important today than it was in the days of bound paper manuscripts.
Abstracts exist to “sell” your work, and they could thus be compared to the “executive summary” of a business resume: an official briefing on what is most important about your research. Or the “gist” of your research. With the majority of academic transactions being conducted online, this means that you have even less time to impress readers–and increased competition in terms of other abstracts out there to read.
The APCI (Academic Publishing and Conferences International) notes that there are 12 questions or “points” considered in the selection process for journals and conferences and stresses the importance of having an abstract that ticks all of these boxes. Because it is often the ONLY chance you have to convince readers to keep reading, it is important that you spend time and energy crafting an abstract that faithfully represents the central parts of your study and captivates your audience.
With that in mind, follow these suggestions when structuring and writing your abstract, and learn how exactly to put these ideas into a solid abstract that will captivate your target readers.
Before Writing Your Abstract
How long should an abstract be.
All abstracts are written with the same essential objective: to give a summary of your study. But there are two basic styles of abstract: descriptive and informative . Here is a brief delineation of the two:
Of the two types of abstracts, informative abstracts are much more common, and they are widely used for submission to journals and conferences. Informative abstracts apply to lengthier and more technical research and are common in the sciences, engineering, and psychology, while descriptive abstracts are more likely used in humanities and social science papers. The best method of determining which abstract type you need to use is to follow the instructions for journal submissions and to read as many other published articles in those journals as possible.
Research Abstract Guidelines and Requirements
As any article about research writing will tell you, authors must always closely follow the specific guidelines and requirements indicated in the Guide for Authors section of their target journal’s website. The same kind of adherence to conventions should be applied to journal publications, for consideration at a conference, and even when completing a class assignment.
Each publisher has particular demands when it comes to formatting and structure. Here are some common questions addressed in the journal guidelines:
- Is there a maximum or minimum word/character length?
- What are the style and formatting requirements?
- What is the appropriate abstract type?
- Are there any specific content or organization rules that apply?
There are of course other rules to consider when composing a research paper abstract. But if you follow the stated rules the first time you submit your manuscript, you can avoid your work being thrown in the “circular file” right off the bat.
Identify Your Target Readership
The main purpose of your abstract is to lead researchers to the full text of your research paper. In scientific journals, abstracts let readers decide whether the research discussed is relevant to their own interests or study. Abstracts also help readers understand your main argument quickly. Consider these questions as you write your abstract:
- Are other academics in your field the main target of your study?
- Will your study perhaps be useful to members of the general public?
- Do your study results include the wider implications presented in the abstract?
Outlining and Writing Your Abstract
What to include in an abstract.
Just as your research paper title should cover as much ground as possible in a few short words, your abstract must cover all parts of your study in order to fully explain your paper and research. Because it must accomplish this task in the space of only a few hundred words, it is important not to include ambiguous references or phrases that will confuse the reader or mislead them about the content and objectives of your research. Follow these dos and don’ts when it comes to what kind of writing to include:
- Avoid acronyms or abbreviations since these will need to be explained in order to make sense to the reader, which takes up valuable abstract space. Instead, explain these terms in the Introduction section of the main text.
- Only use references to people or other works if they are well-known. Otherwise, avoid referencing anything outside of your study in the abstract.
- Never include tables, figures, sources, or long quotations in your abstract; you will have plenty of time to present and refer to these in the body of your paper.
Use keywords in your abstract to focus your topic
A vital search tool is the research paper keywords section, which lists the most relevant terms directly underneath the abstract. Think of these keywords as the “tubes” that readers will seek and enter—via queries on databases and search engines—to ultimately land at their destination, which is your paper. Your abstract keywords should thus be words that are commonly used in searches but should also be highly relevant to your work and found in the text of your abstract. Include 5 to 10 important words or short phrases central to your research in both the abstract and the keywords section.
For example, if you are writing a paper on the prevalence of obesity among lower classes that crosses international boundaries, you should include terms like “obesity,” “prevalence,” “international,” “lower classes,” and “cross-cultural.” These are terms that should net a wide array of people interested in your topic of study. Look at our nine rules for choosing keywords for your research paper if you need more input on this.
Research Paper Abstract Structure
As mentioned above, the abstract (especially the informative abstract) acts as a surrogate or synopsis of your research paper, doing almost as much work as the thousands of words that follow it in the body of the main text. In the hard sciences and most social sciences, the abstract includes the following sections and organizational schema.
Each section is quite compact—only a single sentence or two, although there is room for expansion if one element or statement is particularly interesting or compelling. As the abstract is almost always one long paragraph, the individual sections should naturally merge into one another to create a holistic effect. Use the following as a checklist to ensure that you have included all of the necessary content in your abstract.

1) Identify your purpose and motivation
So your research is about rabies in Brazilian squirrels. Why is this important? You should start your abstract by explaining why people should care about this study—why is it significant to your field and perhaps to the wider world? And what is the exact purpose of your study; what are you trying to achieve? Start by answering the following questions:
- What made you decide to do this study or project?
- Why is this study important to your field or to the lay reader?
- Why should someone read your entire article?
In summary, the first section of your abstract should include the importance of the research and its impact on related research fields or on the wider scientific domain.
2) Explain the research problem you are addressing
Stating the research problem that your study addresses is the corollary to why your specific study is important and necessary. For instance, even if the issue of “rabies in Brazilian squirrels” is important, what is the problem—the “missing piece of the puzzle”—that your study helps resolve?
You can combine the problem with the motivation section, but from a perspective of organization and clarity, it is best to separate the two. Here are some precise questions to address:
- What is your research trying to better understand or what problem is it trying to solve?
- What is the scope of your study—does it try to explain something general or specific?
- What is your central claim or argument?
3) Discuss your research approach
Your specific study approach is detailed in the Methods and Materials section . You have already established the importance of the research, your motivation for studying this issue, and the specific problem your paper addresses. Now you need to discuss how you solved or made progress on this problem—how you conducted your research. If your study includes your own work or that of your team, describe that here. If in your paper you reviewed the work of others, explain this here. Did you use analytic models? A simulation? A double-blind study? A case study? You are basically showing the reader the internal engine of your research machine and how it functioned in the study. Be sure to:
- Detail your research—include methods/type of the study, your variables, and the extent of the work
- Briefly present evidence to support your claim
- Highlight your most important sources
4) Briefly summarize your results
Here you will give an overview of the outcome of your study. Avoid using too many vague qualitative terms (e.g, “very,” “small,” or “tremendous”) and try to use at least some quantitative terms (i.e., percentages, figures, numbers). Save your qualitative language for the conclusion statement. Answer questions like these:
- What did your study yield in concrete terms (e.g., trends, figures, correlation between phenomena)?
- How did your results compare to your hypothesis? Was the study successful?
- Where there any highly unexpected outcomes or were they all largely predicted?
5) State your conclusion
In the last section of your abstract, you will give a statement about the implications and limitations of the study . Be sure to connect this statement closely to your results and not the area of study in general. Are the results of this study going to shake up the scientific world? Will they impact how people see “Brazilian squirrels”? Or are the implications minor? Try not to boast about your study or present its impact as too far-reaching, as researchers and journals will tend to be skeptical of bold claims in scientific papers. Answer one of these questions:
- What are the exact effects of these results on my field? On the wider world?
- What other kind of study would yield further solutions to problems?
- What other information is needed to expand knowledge in this area?
After Completing the First Draft of Your Abstract
Revise your abstract.
The abstract, like any piece of academic writing, should be revised before being considered complete. Check it for grammatical and spelling errors and make sure it is formatted properly.
Get feedback from a peer
Getting a fresh set of eyes to review your abstract is a great way to find out whether you’ve summarized your research well. Find a reader who understands research papers but is not an expert in this field or is not affiliated with your study. Ask your reader to summarize what your study is about (including all key points of each section). This should tell you if you have communicated your key points clearly.
In addition to research peers, consider consulting with a professor or even a specialist or generalist writing center consultant about your abstract. Use any resource that helps you see your work from another perspective.
Consider getting professional editing and proofreading
While peer feedback is quite important to ensure the effectiveness of your abstract content, it may be a good idea to find an academic editor to fix mistakes in grammar, spelling, mechanics, style, or formatting. The presence of basic errors in the abstract may not affect your content, but it might dissuade someone from reading your entire study. Wordvice provides English editing services that both correct objective errors and enhance the readability and impact of your work.
Additional Abstract Rules and Guidelines
Write your abstract after completing your paper.
Although the abstract goes at the beginning of your manuscript, it does not merely introduce your research topic (that is the job of the title), but rather summarizes your entire paper. Writing the abstract last will ensure that it is complete and consistent with the findings and statements in your paper.
Keep your content in the correct order
Both questions and answers should be organized in a standard and familiar way to make the content easier for readers to absorb. Ideally, it should mimic the overall format of your essay and the classic “introduction,” “body,” and “conclusion” form, even if the parts are not neatly divided as such.
Write the abstract from scratch
Because the abstract is a self-contained piece of writing viewed separately from the body of the paper, you should write it separately as well. Never copy and paste direct quotes from the paper and avoid paraphrasing sentences in the paper. Using new vocabulary and phrases will keep your abstract interesting and free of redundancies while conserving space.
Don’t include too many details in the abstract
Again, the density of your abstract makes it incompatible with including specific points other than possibly names or locations. You can make references to terms, but do not explain or define them in the abstract. Try to strike a balance between being specific to your study and presenting a relatively broad overview of your work.
Wordvice Resources
If you think your abstract is fine now but you need input on abstract writing or require English editing services (including paper editing ), then head over to the Wordvice academic resources page, where you will find many more articles, for example on writing the Results , Methods , and Discussion sections of your manuscript, on choosing a title for your paper , or on how to finalize your journal submission with a strong cover letter .
Reference management. Clean and simple.
How to write an abstract

What is an abstract?
General format of an abstract, the content of an abstract, abstract example, abstract style guides, frequently asked questions about writing an abstract, related articles.
An abstract is a summary of the main contents of a paper.
The abstract is the first glimpse that readers get of the content of a research paper. It can influence the popularity of a paper, as a well-written one will attract readers, and a poorly-written one will drive them away.
➡️ Different types of papers may require distinct abstract styles. Visit our guide on the different types of research papers to learn more.
Tip: Always wait until you’ve written your entire paper before you write the abstract.
Before you actually start writing an abstract, make sure to follow these steps:
- Read other papers : find papers with similar topics, or similar methodologies, simply to have an idea of how others have written their abstracts. Notice which points they decided to include, and how in depth they described them.
- Double check the journal requirements : always make sure to review the journal guidelines to format your paper accordingly. Usually, they also specify abstract's formats.
- Write the abstract after you finish writing the paper : you can only write an abstract once you finish writing the whole paper. This way you can include all important aspects, such as scope, methodology, and conclusion.
➡️ Read more about what is a research methodology?
The general format of an abstract includes the following features:
- Between 150-300 words .
- An independent page , after the title page and before the table of contents.
- Concise summary including the aim of the research, methodology , and conclusion .
- Keywords describing the content.
As mentioned before, an abstract is a text that summarizes the main points of a research. Here is a break down of each element that should be included in an abstract:
- Purpose : every abstract should start by describing the main purpose or aim of the research.
- Methods : as a second point, the methodology carried out should be explained.
- Results : then, a concise summary of the results should be included.
- Conclusion : finally, a short outline of the general outcome of the research should be given.
- Keywords : along with the abstract, specific words and phrases related to the topics discussed in the research should be added. These words are usually around five, but the number can vary depending on the journal's guidelines.
This abstract, taken from ScienceDirect , illustrates the ideal structure of an abstract. It has 155 words, it's concise, and it clearly shows the division of elements necessary to write a successful abstract.
This paper explores the implicit assumption in the growing body of literature that social media usage is fundamentally different in business-to-business (B2B) companies than in the extant business-to-consumer (B2C) literature. Sashi's (2012) customer engagement cycle is utilized to compare organizational practices in relation to social media marketing in B2B, B2C, Mixed B2B/B2C and B2B2C business models. Utilizing 449 responses to an exploratory panel based survey instrument, we clearly identify differences in social media usage and its perceived importance as a communications channel. In particular we identify distinct differences in the relationship between social media importance and the perceived effectiveness of social media marketing across business models. Our results indicate that B2B social media usage is distinct from B2C, Mixed and B2B2C business model approaches. Specifically B2B organizational members perceive social media to have a lower overall effectiveness as a channel and identify it as less important for relationship oriented usage than other business models.
The exact format of an abstract depends on the citation style you implement. Whether it’s a well-known style (like APA, IEEE, etc.) or a journal's style, each format has its own guidelines, so make sure you know which style you are using before writing your abstract.
APA is one of the most commonly used styles to format an abstract. Therefore, we created a guide with exact instructions on how to write an abstract in APA style, and a template to download:
📕 APA abstract page: format and template
Additionally, you will find below an IEEE and ASA abstract guide by Purdue Online Writing Lab :
📗 IEEE General Format - Abstract
📘 ASA Manuscript Formatting - Abstract
No. You should always write an abstract once you finish writing the whole paper. This way you can include all important aspects of the paper, such as scope, methodology, and conclusion.
The length of an abstract depends on the formatting style of the paper. For example, APA style calls for 150 to 250 words. Generally, you need between 150-300 words.
No. An abstract has an independent section after the title page and before the table of contents, and should not be included in the table of contents.
Take a look at APA abstract page: format and template for exact details on how to format an abstract in APA style.
You can access any paper through Google Scholar or any other search engine; pick a paper and read the abstract. Abstracts are always freely available to read.

- USC Libraries
- Research Guides
Organizing Your Social Sciences Research Paper
- 3. The Abstract
- Purpose of Guide
- Design Flaws to Avoid
- Independent and Dependent Variables
- Glossary of Research Terms
- Reading Research Effectively
- Narrowing a Topic Idea
- Broadening a Topic Idea
- Extending the Timeliness of a Topic Idea
- Academic Writing Style
- Applying Critical Thinking
- Choosing a Title
- Making an Outline
- Paragraph Development
- Research Process Video Series
- Executive Summary
- The C.A.R.S. Model
- Background Information
- The Research Problem/Question
- Theoretical Framework
- Citation Tracking
- Content Alert Services
- Evaluating Sources
- Primary Sources
- Secondary Sources
- Tiertiary Sources
- Scholarly vs. Popular Publications
- Qualitative Methods
- Quantitative Methods
- Insiderness
- Using Non-Textual Elements
- Limitations of the Study
- Common Grammar Mistakes
- Writing Concisely
- Avoiding Plagiarism
- Footnotes or Endnotes?
- Further Readings
- Generative AI and Writing
- USC Libraries Tutorials and Other Guides
- Bibliography
An abstract summarizes, usually in one paragraph of 300 words or less, the major aspects of the entire paper in a prescribed sequence that includes: 1) the overall purpose of the study and the research problem(s) you investigated; 2) the basic design of the study; 3) major findings or trends found as a result of your analysis; and, 4) a brief summary of your interpretations and conclusions.
Writing an Abstract. The Writing Center. Clarion University, 2009; Writing an Abstract for Your Research Paper. The Writing Center, University of Wisconsin, Madison; Koltay, Tibor. Abstracts and Abstracting: A Genre and Set of Skills for the Twenty-first Century . Oxford, UK: Chandos Publishing, 2010;
Importance of a Good Abstract
Sometimes your professor will ask you to include an abstract, or general summary of your work, with your research paper. The abstract allows you to elaborate upon each major aspect of the paper and helps readers decide whether they want to read the rest of the paper. Therefore, enough key information [e.g., summary results, observations, trends, etc.] must be included to make the abstract useful to someone who may want to examine your work.
How do you know when you have enough information in your abstract? A simple rule-of-thumb is to imagine that you are another researcher doing a similar study. Then ask yourself: if your abstract was the only part of the paper you could access, would you be happy with the amount of information presented there? Does it tell the whole story about your study? If the answer is "no" then the abstract likely needs to be revised.
Farkas, David K. “A Scheme for Understanding and Writing Summaries.” Technical Communication 67 (August 2020): 45-60; How to Write a Research Abstract. Office of Undergraduate Research. University of Kentucky; Staiger, David L. “What Today’s Students Need to Know about Writing Abstracts.” International Journal of Business Communication January 3 (1966): 29-33; Swales, John M. and Christine B. Feak. Abstracts and the Writing of Abstracts . Ann Arbor, MI: University of Michigan Press, 2009.
Structure and Writing Style
I. Types of Abstracts
To begin, you need to determine which type of abstract you should include with your paper. There are four general types.
Critical Abstract A critical abstract provides, in addition to describing main findings and information, a judgment or comment about the study’s validity, reliability, or completeness. The researcher evaluates the paper and often compares it with other works on the same subject. Critical abstracts are generally 400-500 words in length due to the additional interpretive commentary. These types of abstracts are used infrequently.
Descriptive Abstract A descriptive abstract indicates the type of information found in the work. It makes no judgments about the work, nor does it provide results or conclusions of the research. It does incorporate key words found in the text and may include the purpose, methods, and scope of the research. Essentially, the descriptive abstract only describes the work being summarized. Some researchers consider it an outline of the work, rather than a summary. Descriptive abstracts are usually very short, 100 words or less. Informative Abstract The majority of abstracts are informative. While they still do not critique or evaluate a work, they do more than describe it. A good informative abstract acts as a surrogate for the work itself. That is, the researcher presents and explains all the main arguments and the important results and evidence in the paper. An informative abstract includes the information that can be found in a descriptive abstract [purpose, methods, scope] but it also includes the results and conclusions of the research and the recommendations of the author. The length varies according to discipline, but an informative abstract is usually no more than 300 words in length.
Highlight Abstract A highlight abstract is specifically written to attract the reader’s attention to the study. No pretense is made of there being either a balanced or complete picture of the paper and, in fact, incomplete and leading remarks may be used to spark the reader’s interest. In that a highlight abstract cannot stand independent of its associated article, it is not a true abstract and, therefore, rarely used in academic writing.
II. Writing Style
Use the active voice when possible , but note that much of your abstract may require passive sentence constructions. Regardless, write your abstract using concise, but complete, sentences. Get to the point quickly and always use the past tense because you are reporting on a study that has been completed.
Abstracts should be formatted as a single paragraph in a block format and with no paragraph indentations. In most cases, the abstract page immediately follows the title page. Do not number the page. Rules set forth in writing manual vary but, in general, you should center the word "Abstract" at the top of the page with double spacing between the heading and the abstract. The final sentences of an abstract concisely summarize your study’s conclusions, implications, or applications to practice and, if appropriate, can be followed by a statement about the need for additional research revealed from the findings.
Composing Your Abstract
Although it is the first section of your paper, the abstract should be written last since it will summarize the contents of your entire paper. A good strategy to begin composing your abstract is to take whole sentences or key phrases from each section of the paper and put them in a sequence that summarizes the contents. Then revise or add connecting phrases or words to make the narrative flow clearly and smoothly. Note that statistical findings should be reported parenthetically [i.e., written in parentheses].
Before handing in your final paper, check to make sure that the information in the abstract completely agrees with what you have written in the paper. Think of the abstract as a sequential set of complete sentences describing the most crucial information using the fewest necessary words. The abstract SHOULD NOT contain:
- A catchy introductory phrase, provocative quote, or other device to grab the reader's attention,
- Lengthy background or contextual information,
- Redundant phrases, unnecessary adverbs and adjectives, and repetitive information;
- Acronyms or abbreviations,
- References to other literature [say something like, "current research shows that..." or "studies have indicated..."],
- Using ellipticals [i.e., ending with "..."] or incomplete sentences,
- Jargon or terms that may be confusing to the reader,
- Citations to other works, and
- Any sort of image, illustration, figure, or table, or references to them.
Abstract. Writing Center. University of Kansas; Abstract. The Structure, Format, Content, and Style of a Journal-Style Scientific Paper. Department of Biology. Bates College; Abstracts. The Writing Center. University of North Carolina; Borko, Harold and Seymour Chatman. "Criteria for Acceptable Abstracts: A Survey of Abstracters' Instructions." American Documentation 14 (April 1963): 149-160; Abstracts. The Writer’s Handbook. Writing Center. University of Wisconsin, Madison; Hartley, James and Lucy Betts. "Common Weaknesses in Traditional Abstracts in the Social Sciences." Journal of the American Society for Information Science and Technology 60 (October 2009): 2010-2018; Koltay, Tibor. Abstracts and Abstracting: A Genre and Set of Skills for the Twenty-first Century. Oxford, UK: Chandos Publishing, 2010; Procter, Margaret. The Abstract. University College Writing Centre. University of Toronto; Riordan, Laura. “Mastering the Art of Abstracts.” The Journal of the American Osteopathic Association 115 (January 2015 ): 41-47; Writing Report Abstracts. The Writing Lab and The OWL. Purdue University; Writing Abstracts. Writing Tutorial Services, Center for Innovative Teaching and Learning. Indiana University; Koltay, Tibor. Abstracts and Abstracting: A Genre and Set of Skills for the Twenty-First Century . Oxford, UK: 2010; Writing an Abstract for Your Research Paper. The Writing Center, University of Wisconsin, Madison.
Writing Tip
Never Cite Just the Abstract!
Citing to just a journal article's abstract does not confirm for the reader that you have conducted a thorough or reliable review of the literature. If the full-text is not available, go to the USC Libraries main page and enter the title of the article [NOT the title of the journal]. If the Libraries have a subscription to the journal, the article should appear with a link to the full-text or to the journal publisher page where you can get the article. If the article does not appear, try searching Google Scholar using the link on the USC Libraries main page. If you still can't find the article after doing this, contact a librarian or you can request it from our free i nterlibrary loan and document delivery service .
- << Previous: Research Process Video Series
- Next: Executive Summary >>
- Last Updated: May 25, 2024 4:09 PM
- URL: https://libguides.usc.edu/writingguide
How to Write an Abstract APA Format
Saul Mcleod, PhD
Editor-in-Chief for Simply Psychology
BSc (Hons) Psychology, MRes, PhD, University of Manchester
Saul Mcleod, PhD., is a qualified psychology teacher with over 18 years of experience in further and higher education. He has been published in peer-reviewed journals, including the Journal of Clinical Psychology.
Learn about our Editorial Process
Olivia Guy-Evans, MSc
Associate Editor for Simply Psychology
BSc (Hons) Psychology, MSc Psychology of Education
Olivia Guy-Evans is a writer and associate editor for Simply Psychology. She has previously worked in healthcare and educational sectors.
An APA abstract is a brief, comprehensive summary of the contents of an article, research paper, dissertation, or report.
It is written in accordance with the guidelines of the American Psychological Association (APA), which is a widely used format in social and behavioral sciences.
An APA abstract summarizes, usually in one paragraph of between 150–250 words, the major aspects of a research paper or dissertation in a prescribed sequence that includes:
- The rationale: the overall purpose of the study, providing a clear context for the research undertaken.
- Information regarding the method and participants: including materials/instruments, design, procedure, and data analysis.
- Main findings or trends: effectively highlighting the key outcomes of the hypotheses.
- Interpretations and conclusion(s): solidify the implications of the research.
- Keywords related to the study: assist the paper’s discoverability in academic databases.
The abstract should stand alone, be “self-contained,” and make sense to the reader in isolation from the main article.
The purpose of the abstract is to give the reader a quick overview of the essential information before reading the entire article. The abstract is placed on its own page, directly after the title page and before the main body of the paper.
Although the abstract will appear as the very first part of your paper, it’s good practice to write your abstract after you’ve drafted your full paper, so that you know what you’re summarizing.
Note : This page reflects the latest version of the APA Publication Manual (i.e., APA 7), released in October 2019.
Structure of the Abstract
[NOTE: DO NOT separate the components of the abstract – it should be written as a single paragraph. This section is separated to illustrate the abstract’s structure.]
1) The Rationale
One or two sentences describing the overall purpose of the study and the research problem(s) you investigated. You are basically justifying why this study was conducted.
- What is the importance of the research?
- Why would a reader be interested in the larger work?
- For example, are you filling a gap in previous research or applying new methods to take a fresh look at existing ideas or data?
- Women who are diagnosed with breast cancer can experience an array of psychosocial difficulties; however, social support, particularly from a spouse, has been shown to have a protective function during this time. This study examined the ways in which a woman’s daily mood, pain, and fatigue, and her spouse’s marital satisfaction predict the woman’s report of partner support in the context of breast cancer.
- The current nursing shortage, high hospital nurse job dissatisfaction, and reports of uneven quality of hospital care are not uniquely American phenomena.
- Students with special educational needs and disabilities (SEND) are more likely to exhibit behavioral difficulties than their typically developing peers. The aim of this study was to identify specific risk factors that influence variability in behavior difficulties among individuals with SEND.
2) The Method
Information regarding the participants (number, and population). One or two sentences outlining the method, explaining what was done and how. The method is described in the present tense.
- Pretest data from a larger intervention study and multilevel modeling were used to examine the effects of women’s daily mood, pain, and fatigue and average levels of mood, pain, and fatigue on women’s report of social support received from her partner, as well as how the effects of mood interacted with partners’ marital satisfaction.
- This paper presents reports from 43,000 nurses from more than 700 hospitals in the United States, Canada, England, Scotland, and Germany in 1998–1999.
- The study sample comprised 4,228 students with SEND, aged 5–15, drawn from 305 primary and secondary schools across England. Explanatory variables were measured at the individual and school levels at baseline, along with a teacher-reported measure of behavior difficulties (assessed at baseline and the 18-month follow-up).
3) The Results
One or two sentences indicating the main findings or trends found as a result of your analysis. The results are described in the present or past tense.
- Results show that on days in which women reported higher levels of negative or positive mood, as well as on days they reported more pain and fatigue, they reported receiving more support. Women who, on average, reported higher levels of positive mood tended to report receiving more support than those who, on average, reported lower positive mood. However, average levels of negative mood were not associated with support. Higher average levels of fatigue but not pain were associated with higher support. Finally, women whose husbands reported higher levels of marital satisfaction reported receiving more partner support, but husbands’ marital satisfaction did not moderate the effect of women’s mood on support.
- Nurses in countries with distinctly different healthcare systems report similar shortcomings in their work environments and the quality of hospital care. While the competence of and relation between nurses and physicians appear satisfactory, core problems in work design and workforce management threaten the provision of care.
- Hierarchical linear modeling of data revealed that differences between schools accounted for between 13% (secondary) and 15.4% (primary) of the total variance in the development of students’ behavior difficulties, with the remainder attributable to individual differences. Statistically significant risk markers for these problems across both phases of education were being male, eligibility for free school meals, being identified as a bully, and lower academic achievement. Additional risk markers specific to each phase of education at the individual and school levels are also acknowledged.
4) The Conclusion / Implications
A brief summary of your conclusions and implications of the results, described in the present tense. Explain the results and why the study is important to the reader.
- For example, what changes should be implemented as a result of the findings of the work?
- How does this work add to the body of knowledge on the topic?
Implications of these findings are discussed relative to assisting couples during this difficult time in their lives.
- Resolving these issues, which are amenable to managerial intervention, is essential to preserving patient safety and care of consistently high quality.
- Behavior difficulties are affected by risks across multiple ecological levels. Addressing any one of these potential influences is therefore likely to contribute to the reduction in the problems displayed.
The above examples of abstracts are from the following papers:
Aiken, L. H., Clarke, S. P., Sloane, D. M., Sochalski, J. A., Busse, R., Clarke, H., … & Shamian, J. (2001). Nurses’ reports on hospital care in five countries . Health affairs, 20(3) , 43-53.
Boeding, S. E., Pukay-Martin, N. D., Baucom, D. H., Porter, L. S., Kirby, J. S., Gremore, T. M., & Keefe, F. J. (2014). Couples and breast cancer: Women’s mood and partners’ marital satisfaction predicting support perception . Journal of Family Psychology, 28(5) , 675.
Oldfield, J., Humphrey, N., & Hebron, J. (2017). Risk factors in the development of behavior difficulties among students with special educational needs and disabilities: A multilevel analysis . British journal of educational psychology, 87(2) , 146-169.
5) Keywords
APA style suggests including a list of keywords at the end of the abstract. This is particularly common in academic articles and helps other researchers find your work in databases.
Keywords in an abstract should be selected to help other researchers find your work when searching an online database. These keywords should effectively represent the main topics of your study. Here are some tips for choosing keywords:
Core Concepts: Identify the most important ideas or concepts in your paper. These often include your main research topic, the methods you’ve used, or the theories you’re discussing.
Specificity: Your keywords should be specific to your research. For example, suppose your paper is about the effects of climate change on bird migration patterns in a specific region. In that case, your keywords might include “climate change,” “bird migration,” and the region’s name.
Consistency with Paper: Make sure your keywords are consistent with the terms you’ve used in your paper. For example, if you use the term “adolescent” rather than “teen” in your paper, choose “adolescent” as your keyword, not “teen.”
Jargon and Acronyms: Avoid using too much-specialized jargon or acronyms in your keywords, as these might not be understood or used by all researchers in your field.
Synonyms: Consider including synonyms of your keywords to capture as many relevant searches as possible. For example, if your paper discusses “post-traumatic stress disorder,” you might include “PTSD” as a keyword.
Remember, keywords are a tool for others to find your work, so think about what terms other researchers might use when searching for papers on your topic.
The Abstract SHOULD NOT contain:
Lengthy background or contextual information: The abstract should focus on your research and findings, not general topic background.
Undefined jargon, abbreviations, or acronyms: The abstract should be accessible to a wide audience, so avoid highly specialized terms without defining them.
Citations: Abstracts typically do not include citations, as they summarize original research.
Incomplete sentences or bulleted lists: The abstract should be a single, coherent paragraph written in complete sentences.
New information not covered in the paper: The abstract should only summarize the paper’s content.
Subjective comments or value judgments: Stick to objective descriptions of your research.
Excessive details on methods or procedures: Keep descriptions of methods brief and focused on main steps.
Speculative or inconclusive statements: The abstract should state the research’s clear findings, not hypotheses or possible interpretations.
- Any illustration, figure, table, or references to them . All visual aids, data, or extensive details should be included in the main body of your paper, not in the abstract.
- Elliptical or incomplete sentences should be avoided in an abstract . The use of ellipses (…), which could indicate incomplete thoughts or omitted text, is not appropriate in an abstract.
APA Style for Abstracts
An APA abstract must be formatted as follows:
Include the running head aligned to the left at the top of the page (professional papers only) and page number. Note, student papers do not require a running head. On the first line, center the heading “Abstract” and bold (do not underlined or italicize). Do not indent the single abstract paragraph (which begins one line below the section title). Double-space the text. Use Times New Roman font in 12 pt. Set one-inch (or 2.54 cm) margins. If you include a “keywords” section at the end of the abstract, indent the first line and italicize the word “Keywords” while leaving the keywords themselves without any formatting.
Example APA Abstract Page
Download this example as a PDF

Further Information
- APA 7th Edition Abstract and Keywords Guide
- Example APA Abstract
- How to Write a Good Abstract for a Scientific Paper or Conference Presentation
- How to Write a Lab Report
- Writing an APA paper
How long should an APA abstract be?
An APA abstract should typically be between 150 to 250 words long. However, the exact length may vary depending on specific publication or assignment guidelines. It is crucial that it succinctly summarizes the essential elements of the work, including purpose, methods, findings, and conclusions.
Where does the abstract go in an APA paper?
In an APA formatted paper, the abstract is placed on its own page, directly after the title page and before the main body of the paper. It’s typically the second page of the document. It starts with the word “Abstract” (centered and not in bold) at the top of the page, followed by the text of the abstract itself.
What are the 4 C’s of abstract writing?
The 4 C’s of abstract writing are an approach to help you create a well-structured and informative abstract. They are:
Conciseness: An abstract should briefly summarize the key points of your study. Stick to the word limit (typically between 150-250 words for an APA abstract) and avoid unnecessary details.
Clarity: Your abstract should be easy to understand. Avoid jargon and complex sentences. Clearly explain the purpose, methods, results, and conclusions of your study.
Completeness: Even though it’s brief, the abstract should provide a complete overview of your study, including the purpose, methods, key findings, and your interpretation of the results.
Cohesion: The abstract should flow logically from one point to the next, maintaining a coherent narrative about your study. It’s not just a list of disjointed elements; it’s a brief story of your research from start to finish.
What is the abstract of a psychology paper?
An abstract in a psychology paper serves as a snapshot of the paper, allowing readers to quickly understand the purpose, methodology, results, and implications of the research without reading the entire paper. It is generally between 150-250 words long.
Related Articles

Student Resources
How To Cite A YouTube Video In APA Style – With Examples

APA References Page Formatting and Example
 Format, Example, & Templates 8")
APA Title Page (Cover Page) Format, Example, & Templates

How do I Cite a Source with Multiple Authors in APA Style?

How to Write a Psychology Essay

Lab Report Format: Step-by-Step Guide & Examples

Role of an Abstract in Research Paper With Examples
Why does one write an abstract? What is so intriguing about writing an abstract in research paper after writing a full length research paper? How do research paper abstracts or summaries help a researcher during research publishing? These are the most common and frequently pondered upon questions that early career researchers search answers for over the internet!
Table of Contents
What does Abstract mean in Research?
In Research, abstract is “a well-developed single paragraph which is approximately 250 words in length”. Furthermore, it is single-spaced single spaced. Abstract outlines all the parts of the paper briefly. Although the abstract is placed in the beginning of the research paper immediately after research title , the abstract is the last thing a researcher writes.
Why Is an Abstract Necessary in Research Paper?
Abstract is a concise academic text that –
- Helps the potential reader get the relevance of your research study for their own research
- Communicates your key findings for those who have time constraints in reading your paper
- And helps rank the article on search engines based on the keywords on academic databases.
Purpose of Writing an Abstract in Research
Abstracts are required for –
- Submission of articles to journals
- Application for research grants
- Completion and submission of thesis
- Submission of proposals for conference papers.
Aspects Included in an Abstract
The format of your abstract depends on the field of research, in which you are working. However, all abstracts broadly cover the following sections:
Reason for Writing
One can start with the importance of conducting their research study. Furthermore, you could start with a broader research question and address why would the reader be interested in that particular research question.
Research Problem
You could mention what problem the research study chooses to address. Moreover, you could elaborate about the scope of the project, the main argument, brief about thesis objective or what the study claims.
- Methodology
Furthermore, you could mention a line or two about what approach and specific models the research study uses in the scientific work. Some research studies may discuss the evidences in throughout the paper, so instead of writing about methodologies you could mention the types of evidence used in the research.
The scientific research aims to get the specific data that indicates the results of the project. Therefore, you could mention the results and discuss the findings in a broader and general way.
Finally, you could discuss how the research work contributes to the scientific society and adds knowledge on the topic. Also, you could specify if your findings or inferences could help future research and researchers.
Types of Abstracts
Based on the abstract content —, 1. descriptive.
This abstract in research paper is usually short (50-100 words). These abstracts have common sections, such as –
- Focus of research
- Overview of the study.
This type of research does not include detailed presentation of results and only mention results through a phrase without contributing numerical or statistical data . Descriptive abstracts guide readers on the nature of contents of the article.
2. Informative
This abstract gives the essence of what the report is about and it is usually about 200 words. These abstracts have common sections, such as –
- Aim or purpose
This abstract provides an accurate data on the contents of the work, especially on the results section.
Based on the writing format —
1. structured.
This type of abstract has a paragraph for each section: Introduction, Materials and Methods, Results, and Conclusion. Also, structured abstracts are often required for informative abstracts.
2. Semi-structured
A semi-structured abstract is written in only one paragraph, wherein each sentence corresponds to a section. Furthermore, all the sections mentioned in the structured abstract are present in the semi-structured abstract.
3. Non-structured
In a non-structured abstract there are no divisions between each section. The sentences are included in a single paragraph. This type of presentation is ideal for descriptive abstracts.
Examples of Abstracts
Abstract example 1: clinical research.
Neutralization of Omicron BA.1, BA.2, and BA.3 SARS-CoV-2 by 3 doses of BNT162b2 vaccine
Abstract: The newly emerged Omicron SARS-CoV-2 has several distinct sublineages including BA.1, BA.2, and BA.3. BA.1 accounts for the initial surge and is being replaced by BA.2, whereas BA.3 is at a low prevalence at this time. Here we report the neutralization of BNT162b2-vaccinated sera (collected 1 month after dose 3) against the three Omicron sublineages. To facilitate the neutralization testing, we have engineered the complete BA.1, BA.2, or BA.3 spike into an mNeonGreen USA-WA1/2020 SARS-CoV-2. All BNT162b2-vaccinated sera neutralize USA-WA1/2020, BA.1-, BA.2-, and BA.3-spike SARS-CoV-2s with titers of >20; the neutralization geometric mean titers (GMTs) against the four viruses are 1211, 336, 300, and 190, respectively. Thus, the BA.1-, BA.2-, and BA.3-spike SARS-CoV-2s are 3.6-, 4.0-, and 6.4-fold less efficiently neutralized than the USA-WA1/2020, respectively. Our data have implications in vaccine strategy and understanding the biology of Omicron sublineages.
Type of Abstract: Informative and non-structured
Abstract Example 2: Material Science and Chemistry
Breaking the nanoparticle’s dispersible limit via rotatable surface ligands
Abstract: Achieving versatile dispersion of nanoparticles in a broad range of solvents (e.g., water, oil, and biofluids) without repeatedly recourse to chemical modifications are desirable in optoelectronic devices, self-assembly, sensing, and biomedical fields. However, such a target is limited by the strategies used to decorate nanoparticle’s surface properties, leading to a narrow range of solvents for existing nanoparticles. Here we report a concept to break the nanoparticle’s dispersible limit via electrochemically anchoring surface ligands capable of sensing the surrounding liquid medium and rotating to adapt to it, immediately forming stable dispersions in a wide range of solvents (polar and nonpolar, biofluids, etc.). Moreover, the smart nanoparticles can be continuously electrodeposited in the electrolyte, overcoming the electrode surface-confined low throughput limitation of conventional electrodeposition methods. The anomalous dispersive property of the smart Ag nanoparticles enables them to resist bacteria secreted species-induced aggregation and the structural similarity of the surface ligands to that of the bacterial membrane assists them to enter the bacteria, leading to high antibacterial activity. The simple but massive fabrication process and the enhanced dispersion properties offer great application opportunities to the smart nanoparticles in diverse fields.
Type of Abstract: Descriptive and non-structured
Abstract Example 3: Clinical Toxicology
Evaluation of dexmedetomidine therapy for sedation in patients with toxicological events at an academic medical center
Introduction: Although clinical use of dexmedetomidine (DEX), an alpha2-adrenergic receptor agonist, has increased, its role in patients admitted to intensive care units secondary to toxicological sequelae has not been well established.
Objectives: The primary objective of this study was to describe clinical and adverse effects observed in poisoned patients receiving DEX for sedation.
Methods: This was an observational case series with retrospective chart review of poisoned patients who received DEX for sedation at an academic medical center. The primary endpoint was incidence of adverse effects of DEX therapy including bradycardia, hypotension, seizures, and arrhythmias. For comparison, vital signs were collected hourly for the 5 h preceding the DEX therapy and every hour during DEX therapy until the therapy ended. Additional endpoints included therapy duration; time within target Richmond Agitation Sedation Score (RASS); and concomitant sedation, analgesia, and vasopressor requirements.
Results: Twenty-two patients were included. Median initial and median DEX infusion rates were similar to the commonly used rates for sedation. Median heart rate was lower during the therapy (82 vs. 93 beats/minute, p < 0.05). Median systolic blood pressure before and during therapy was similar (111 vs. 109 mmHg, p = 0.745). Five patients experienced an adverse effect per study definitions during therapy. No additional adverse effects were noted. Median time within target RASS and duration of therapy was 6.5 and 44.5 h, respectively. Seventeen patients (77%) had concomitant use of other sedation and/or analgesia with four (23%) of these patients requiring additional agents after DEX initiation. Seven patients (32%) had concomitant vasopressor support with four (57%) of these patients requiring vasopressor support after DEX initiation.
Conclusion: Common adverse effects of DEX were noted in this study. The requirement for vasopressor support during therapy warrants further investigation into the safety of DEX in poisoned patients. Larger, comparative studies need to be performed before the use of DEX can be routinely recommended in poisoned patients.
Keywords: Adverse effects; Alpha2-adrenergic receptor agonist; Overdose; Safety.
Type of Abstract: Informative and structured .
How was your experience writing an abstract? What type of abstracts have you written? Do write to us or leave a comment below.
Rate this article Cancel Reply
Your email address will not be published.

Enago Academy's Most Popular Articles

- Reporting Research
Academic Essay Writing Made Simple: 4 types and tips
The pen is mightier than the sword, they say, and nowhere is this more evident…

- AI in Academia
- Trending Now
Simplifying the Literature Review Journey — A comparative analysis of 6 AI summarization tools
Imagine having to skim through and read mountains of research papers and books, only to…

Choosing the Right Analytical Approach: Thematic analysis vs. content analysis for data interpretation
In research, choosing the right approach to understand data is crucial for deriving meaningful insights.…

Comparing Cross Sectional and Longitudinal Studies: 5 steps for choosing the right approach
The process of choosing the right research design can put ourselves at the crossroads of…

- Career Corner
Unlocking the Power of Networking in Academic Conferences
Embarking on your first academic conference experience? Fear not, we got you covered! Academic conferences…
Choosing the Right Analytical Approach: Thematic analysis vs. content analysis for…
Comparing Cross Sectional and Longitudinal Studies: 5 steps for choosing the right…
Research Recommendations – Guiding policy-makers for evidence-based decision making

Sign-up to read more
Subscribe for free to get unrestricted access to all our resources on research writing and academic publishing including:
- 2000+ blog articles
- 50+ Webinars
- 10+ Expert podcasts
- 50+ Infographics
- 10+ Checklists
- Research Guides
We hate spam too. We promise to protect your privacy and never spam you.
I am looking for Editing/ Proofreading services for my manuscript Tentative date of next journal submission:

As a researcher, what do you consider most when choosing an image manipulation detector?

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
Preview improvements coming to the PMC website in October 2024. Learn More or Try it out now .
- Advanced Search
- Journal List
- Indian J Psychiatry
- v.53(2); Apr-Jun 2011
How to write a good abstract for a scientific paper or conference presentation
Chittaranjan andrade.
Department of Psychopharmacology, National Institute of Mental Health and Neurosciences, Bangalore, Karnataka, India
Abstracts of scientific papers are sometimes poorly written, often lack important information, and occasionally convey a biased picture. This paper provides detailed suggestions, with examples, for writing the background, methods, results, and conclusions sections of a good abstract. The primary target of this paper is the young researcher; however, authors with all levels of experience may find useful ideas in the paper.
INTRODUCTION
This paper is the third in a series on manuscript writing skills, published in the Indian Journal of Psychiatry . Earlier articles offered suggestions on how to write a good case report,[ 1 ] and how to read, write, or review a paper on randomized controlled trials.[ 2 , 3 ] The present paper examines how authors may write a good abstract when preparing their manuscript for a scientific journal or conference presentation. Although the primary target of this paper is the young researcher, it is likely that authors with all levels of experience will find at least a few ideas that may be useful in their future efforts.
The abstract of a paper is the only part of the paper that is published in conference proceedings. The abstract is the only part of the paper that a potential referee sees when he is invited by an editor to review a manuscript. The abstract is the only part of the paper that readers see when they search through electronic databases such as PubMed. Finally, most readers will acknowledge, with a chuckle, that when they leaf through the hard copy of a journal, they look at only the titles of the contained papers. If a title interests them, they glance through the abstract of that paper. Only a dedicated reader will peruse the contents of the paper, and then, most often only the introduction and discussion sections. Only a reader with a very specific interest in the subject of the paper, and a need to understand it thoroughly, will read the entire paper.
Thus, for the vast majority of readers, the paper does not exist beyond its abstract. For the referees, and the few readers who wish to read beyond the abstract, the abstract sets the tone for the rest of the paper. It is therefore the duty of the author to ensure that the abstract is properly representative of the entire paper. For this, the abstract must have some general qualities. These are listed in Table 1 .
General qualities of a good abstract

SECTIONS OF AN ABSTRACT
Although some journals still publish abstracts that are written as free-flowing paragraphs, most journals require abstracts to conform to a formal structure within a word count of, usually, 200–250 words. The usual sections defined in a structured abstract are the Background, Methods, Results, and Conclusions; other headings with similar meanings may be used (eg, Introduction in place of Background or Findings in place of Results). Some journals include additional sections, such as Objectives (between Background and Methods) and Limitations (at the end of the abstract). In the rest of this paper, issues related to the contents of each section will be examined in turn.
This section should be the shortest part of the abstract and should very briefly outline the following information:
- What is already known about the subject, related to the paper in question
- What is not known about the subject and hence what the study intended to examine (or what the paper seeks to present)
In most cases, the background can be framed in just 2–3 sentences, with each sentence describing a different aspect of the information referred to above; sometimes, even a single sentence may suffice. The purpose of the background, as the word itself indicates, is to provide the reader with a background to the study, and hence to smoothly lead into a description of the methods employed in the investigation.
Some authors publish papers the abstracts of which contain a lengthy background section. There are some situations, perhaps, where this may be justified. In most cases, however, a longer background section means that less space remains for the presentation of the results. This is unfortunate because the reader is interested in the paper because of its findings, and not because of its background.
A wide variety of acceptably composed backgrounds is provided in Table 2 ; most of these have been adapted from actual papers.[ 4 – 9 ] Readers may wish to compare the content in Table 2 with the original abstracts to see how the adaptations possibly improve on the originals. Note that, in the interest of brevity, unnecessary content is avoided. For instance, in Example 1 there is no need to state “The antidepressant efficacy of desvenlafaxine (DV), a dual-acting antidepressant drug , has been established…” (the unnecessary content is italicized).
Examples of the background section of an abstract

The methods section is usually the second-longest section in the abstract. It should contain enough information to enable the reader to understand what was done, and how. Table 3 lists important questions to which the methods section should provide brief answers.
Questions regarding which information should ideally be available in the methods section of an abstract

Carelessly written methods sections lack information about important issues such as sample size, numbers of patients in different groups, doses of medications, and duration of the study. Readers have only to flip through the pages of a randomly selected journal to realize how common such carelessness is.
Table 4 presents examples of the contents of accept-ably written methods sections, modified from actual publications.[ 10 , 11 ] Readers are invited to take special note of the first sentence of each example in Table 4 ; each is packed with detail, illustrating how to convey the maximum quantity of information with maximum economy of word count.
Examples of the methods section of an abstract

The results section is the most important part of the abstract and nothing should compromise its range and quality. This is because readers who peruse an abstract do so to learn about the findings of the study. The results section should therefore be the longest part of the abstract and should contain as much detail about the findings as the journal word count permits. For example, it is bad writing to state “Response rates differed significantly between diabetic and nondiabetic patients.” A better sentence is “The response rate was higher in nondiabetic than in diabetic patients (49% vs 30%, respectively; P <0.01).”
Important information that the results should present is indicated in Table 5 . Examples of acceptably written abstracts are presented in Table 6 ; one of these has been modified from an actual publication.[ 11 ] Note that the first example is rather narrative in style, whereas the second example is packed with data.
Information that the results section of the abstract should ideally present

Examples of the results section of an abstract

CONCLUSIONS
This section should contain the most important take-home message of the study, expressed in a few precisely worded sentences. Usually, the finding highlighted here relates to the primary outcome measure; however, other important or unexpected findings should also be mentioned. It is also customary, but not essential, for the authors to express an opinion about the theoretical or practical implications of the findings, or the importance of their findings for the field. Thus, the conclusions may contain three elements:
- The primary take-home message
- The additional findings of importance
- The perspective
Despite its necessary brevity, this section has the most impact on the average reader because readers generally trust authors and take their assertions at face value. For this reason, the conclusions should also be scrupulously honest; and authors should not claim more than their data demonstrate. Hypothetical examples of the conclusions section of an abstract are presented in Table 7 .
Examples of the conclusions section of an abstract

MISCELLANEOUS OBSERVATIONS
Citation of references anywhere within an abstract is almost invariably inappropriate. Other examples of unnecessary content in an abstract are listed in Table 8 .
Examples of unnecessary content in a abstract

It goes without saying that whatever is present in the abstract must also be present in the text. Likewise, whatever errors should not be made in the text should not appear in the abstract (eg, mistaking association for causality).
As already mentioned, the abstract is the only part of the paper that the vast majority of readers see. Therefore, it is critically important for authors to ensure that their enthusiasm or bias does not deceive the reader; unjustified speculations could be even more harmful. Misleading readers could harm the cause of science and have an adverse impact on patient care.[ 12 ] A recent study,[ 13 ] for example, concluded that venlafaxine use during the second trimester of pregnancy may increase the risk of neonates born small for gestational age. However, nowhere in the abstract did the authors mention that these conclusions were based on just 5 cases and 12 controls out of the total sample of 126 cases and 806 controls. There were several other serious limitations that rendered the authors’ conclusions tentative, at best; yet, nowhere in the abstract were these other limitations expressed.
As a parting note: Most journals provide clear instructions to authors on the formatting and contents of different parts of the manuscript. These instructions often include details on what the sections of an abstract should contain. Authors should tailor their abstracts to the specific requirements of the journal to which they plan to submit their manuscript. It could also be an excellent idea to model the abstract of the paper, sentence for sentence, on the abstract of an important paper on a similar subject and with similar methodology, published in the same journal for which the manuscript is slated.
Source of Support: Nil
Conflict of Interest: None declared.

Magnum Proofreading Services
- Jake Magnum
- Jan 2, 2021
Writing an Abstract for a Research Paper: Guidelines, Examples, and Templates
There are six steps to writing a standard abstract. (1) Begin with a broad statement about your topic. Then, (2) state the problem or knowledge gap related to this topic that your study explores. After that, (3) describe what specific aspect of this problem you investigated, and (4) briefly explain how you went about doing this. After that, (5) describe the most meaningful outcome(s) of your study. Finally, (6) close your abstract by explaining the broad implication(s) of your findings.
In this article, I present step-by-step guidelines for writing an abstract for an academic paper. These guidelines are fo llowed by an example of a full abstract that follows these guidelines and a few fill-in-the-blank templates that you can use to write your own abstract.
Guidelines for Writing an Abstract
The basic structure of an abstract is illustrated below.
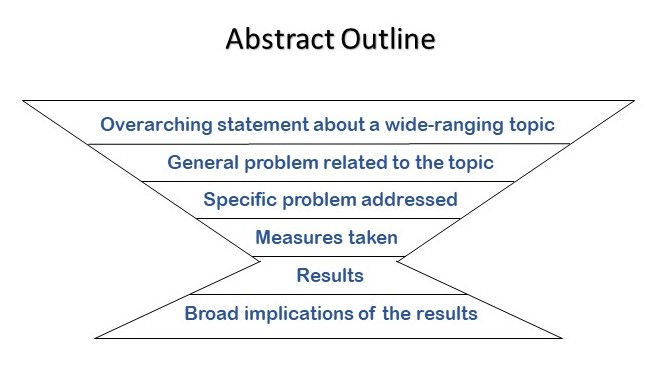
A standard abstract starts with a very general statement and becomes more specific with each sentence that follows until once again making a broad statement about the study’s implications at the end. Altogether, a standard abstract has six functions, which are described in detail below.
Start by making a broad statement about your topic.
The first sentence of your abstract should briefly describe a problem that is of interest to your readers. When writing this first sentence, you should think about who comprises your target audience and use terms that will appeal to this audience. If your opening sentence is too broad, it might lose the attention of potential readers because they will not know if your study is relevant to them.
Too broad : Maintaining an ideal workplace environment has a positive effect on employees.
The sentence above is so broad that it will not grab the reader’s attention. While it gives the reader some idea of the area of study, it doesn’t provide any details about the author’s topic within their research area. This can be fixed by inserting some keywords related to the topic (these are underlined in the revised example below).
Improved : Keeping the workplace environment at an ideal temperature positively affects the overall health of employees.
The revised sentence is much better, as it expresses two points about the research topic—namely, (i) what aspect of workplace environment was studied, (ii) what aspect of employees was observed. The mention of these aspects of the research will draw the attention of readers who are interested in them.
Describe the general problem that your paper addresses.
After describing your topic in the first sentence, you can then explain what aspect of this topic has motivated your research. Often, authors use this part of the abstract to describe the research gap that they identified and aimed to fill. These types of sentences are often characterized by the use of words such as “however,” “although,” “despite,” and so on.
However, a comprehensive understanding of how different workplace bullying experiences are associated with absenteeism is currently lacking.
The above example is typical of a sentence describing the problem that a study intends to tackle. The author has noticed that there is a gap in the research, and they briefly explain this gap here.
Although it has been established that quantity and quality of sleep can affect different types of task performance and personal health, the interactions between sleep habits and workplace behaviors have received very little attention.
The example above illustrates a case in which the author has accomplished two tasks with one sentence. The first part of the sentence (up until the comma) mentions the general topic that the research fits into, while the second part (after the comma) describes the general problem that the research addresses.
Express the specific problem investigated in your paper.
After describing the general problem that motivated your research, the next sentence should express the specific aspect of the problem that you investigated. Sentences of this type are often indicated by the use of phrases like “the purpose of this research is to,” “this paper is intended to,” or “this work aims to.”
Uninformative : However, a comprehensive understanding of how different workplace bullying experiences are associated with absenteeism is currently lacking. The present article aimed to provide new insights into the relationship between workplace bullying and absenteeism .
The second sentence in the above example is a mere rewording of the first sentence. As such, it adds nothing to the abstract. The second sentence should be more specific than the preceding one.
Improved : However, a comprehensive understanding of how different workplace bullying experiences are associated with absenteeism is currently lacking. The present article aimed to define various subtypes of workplace bullying and determine which subtypes tend to lead to absenteeism .
The second sentence of this passage is much more informative than in the previous example. This sentence lets the reader know exactly what they can expect from the full research article.
Explain how you attempted to resolve your study’s specific problem.
In this part of your abstract, you should attempt to describe your study’s methodology in one or two sentences. As such, you must be sure to include only the most important information about your method. At the same time, you must also be careful not to be too vague.
Too vague : We conducted multiple tests to examine changes in various factors related to well-being.
This description of the methodology is too vague. Instead of merely mentioning “tests” and “factors,” the author should note which specific tests were run and which factors were assessed.
Improved : Using data from BHIP completers, we conducted multiple one-way multivariate analyses of variance and follow-up univariate t-tests to examine changes in physical and mental health, stress, energy levels, social satisfaction, self-efficacy, and quality of life.
This sentence is very well-written. It packs a lot of specific information about the method into a single sentence. Also, it does not describe more details than are needed for an abstract.
Briefly tell the reader what you found by carrying out your study.
This is the most important part of the abstract—the other sentences in the abstract are there to explain why this one is relevant. When writing this sentence, imagine that someone has asked you, “What did you find in your research?” and that you need to answer them in one or two sentences.
Too vague : Consistently poor sleepers had more health risks and medical conditions than consistently optimal sleepers.
This sentence is okay, but it would be helpful to let the reader know which health risks and medical conditions were related to poor sleeping habits.
Improved : Consistently poor sleepers were more likely than consistently optimal sleepers to suffer from chronic abdominal pain, and they were at a higher risk for diabetes and heart disease.
This sentence is better, as the specific health conditions are named.
Finally, describe the major implication(s) of your study.
Most abstracts end with a short sentence that explains the main takeaway(s) that you want your audience to gain from reading your paper. Often, this sentence is addressed to people in power (e.g., employers, policymakers), and it recommends a course of action that such people should take based on the results.
Too broad : Employers may wish to make use of strategies that increase employee health.
This sentence is too broad to be useful. It does not give employers a starting point to implement a change.
Improved : Employers may wish to incorporate sleep education initiatives as part of their overall health and wellness strategies.
This sentence is better than the original, as it provides employers with a starting point—specifically, it invites employers to look up information on sleep education programs.
Abstract Example
The abstract produced here is from a paper published in Electronic Commerce Research and Applications . I have made slight alterations to the abstract so that this example fits the guidelines given in this article.
(1) Gamification can strengthen enjoyment and productivity in the workplace. (2) Despite this, research on gamification in the work context is still limited. (3) In this study, we investigated the effect of gamification on the workplace enjoyment and productivity of employees by comparing employees with leadership responsibilities to those without leadership responsibilities. (4) Work-related tasks were gamified using the habit-tracking game Habitica, and data from 114 employees were gathered using an online survey. (5) The results illustrated that employees without leadership responsibilities used work gamification as a trigger for self-motivation, whereas employees with leadership responsibilities used it to improve their health. (6) Work gamification positively affected work enjoyment for both types of employees and positively affected productivity for employees with leadership responsibilities. (7) Our results underline the importance of taking work-related variables into account when researching work gamification.
In Sentence (1), the author makes a broad statement about their topic. Notice how the nouns used (“gamification,” “enjoyment,” “productivity”) are quite general while still indicating the focus of the paper. The author uses Sentence (2) to very briefly state the problem that the research will address.
In Sentence (3), the author explains what specific aspects of the problem mentioned in Sentence (2) will be explored in the present work. Notice that the mention of leadership responsibilities makes Sentence (3) more specific than Sentence (2). Sentence (4) gets even more specific, naming the specific tools used to gather data and the number of participants.
Sentences (5) and (6) are similar, with each sentence describing one of the study’s main findings. Then, suddenly, the scope of the abstract becomes quite broad again in Sentence (7), which mentions “work-related variables” instead of a specific variable and “researching” instead of a specific kind of research.
Abstract Templates
Copy and paste any of the paragraphs below into a word processor. Then insert the appropriate information to produce an abstract for your research paper.
Template #1
Researchers have established that [Make a broad statement about your area of research.] . However, [Describe the knowledge gap that your paper addresses.] . The goal of this paper is to [Describe the purpose of your paper.] . The achieve this goal, we [Briefly explain your methodology.] . We found that [Indicate the main finding(s) of your study; you may need two sentences to do this.] . [Provide a broad implication of your results.] .
Template #2
It is well-understood that [Make a broad statement about your area of research.] . Despite this, [Describe the knowledge gap that your paper addresses.] . The current research aims to [Describe the purpose of your paper.] . To accomplish this, we [Briefly explain your methodology.] . It was discovered that [Indicate the main finding(s) of your study; you may need two sentences to do this.] . [Provide a broad implication of your results.] .
Template #3
Extensive research indicates that [Make a broad statement about your area of research.] . Nevertheless, [Describe the knowledge gap that your paper addresses.] . The present work is intended to [Describe the purpose of your paper.] . To this end, we [Briefly explain your methodology.] . The results revealed that [Indicate the main finding(s) of your study; you may need two sentences to do this.] . [Provide a broad implication of your results.] .
- How to Write an Abstract
Related Posts
How to Write a Research Paper in English: A Guide for Non-native Speakers
How to Write an Abstract Quickly
Using the Present Tense and Past Tense When Writing an Abstract
Well explained! I have given you a credit
Academic & Employability Skills
Subscribe to academic & employability skills.
Enter your email address to subscribe to this blog and receive notifications of new posts by email.
Join 412 other subscribers.
Email Address

Writing an abstract - a six point checklist (with samples)
Posted in: abstract , dissertations

The abstract is a vital part of any research paper. It is the shop front for your work, and the first stop for your reader. It should provide a clear and succinct summary of your study, and encourage your readers to read more. An effective abstract, therefore should answer the following questions:
- Why did you do this study or project?
- What did you do and how?
- What did you find?
- What do your findings mean?
So here's our run down of the key elements of a well-written abstract.
- Size - A succinct and well written abstract should be between approximately 100- 250 words.
- Background - An effective abstract usually includes some scene-setting information which might include what is already known about the subject, related to the paper in question (a few short sentences).
- Purpose - The abstract should also set out the purpose of your research, in other words, what is not known about the subject and hence what the study intended to examine (or what the paper seeks to present).
- Methods - The methods section should contain enough information to enable the reader to understand what was done, and how. It should include brief details of the research design, sample size, duration of study, and so on.
- Results - The results section is the most important part of the abstract. This is because readers who skim an abstract do so to learn about the findings of the study. The results section should therefore contain as much detail about the findings as the journal word count permits.
- Conclusion - This section should contain the most important take-home message of the study, expressed in a few precisely worded sentences. Usually, the finding highlighted here relates to the primary outcomes of the study. However, other important or unexpected findings should also be mentioned. It is also customary, but not essential, to express an opinion about the theoretical or practical implications of the findings, or the importance of their findings for the field. Thus, the conclusions may contain three elements:
- The primary take-home message.
- Any additional findings of importance.
- Implications for future studies.

Example Abstract 2: Engineering Development and validation of a three-dimensional finite element model of the pelvic bone.

Abstract from: Dalstra, M., Huiskes, R. and Van Erning, L., 1995. Development and validation of a three-dimensional finite element model of the pelvic bone. Journal of biomechanical engineering, 117(3), pp.272-278.
And finally... A word on abstract types and styles
Abstract types can differ according to subject discipline. You need to determine therefore which type of abstract you should include with your paper. Here are two of the most common types with examples.
Informative Abstract
The majority of abstracts are informative. While they still do not critique or evaluate a work, they do more than describe it. A good informative abstract acts as a surrogate for the work itself. That is, the researcher presents and explains all the main arguments and the important results and evidence in the paper. An informative abstract includes the information that can be found in a descriptive abstract [purpose, methods, scope] but it also includes the results and conclusions of the research and the recommendations of the author. The length varies according to discipline, but an informative abstract is usually no more than 300 words in length.
Descriptive Abstract A descriptive abstract indicates the type of information found in the work. It makes no judgements about the work, nor does it provide results or conclusions of the research. It does incorporate key words found in the text and may include the purpose, methods, and scope of the research. Essentially, the descriptive abstract only describes the work being summarised. Some researchers consider it an outline of the work, rather than a summary. Descriptive abstracts are usually very short, 100 words or less.
Adapted from Andrade C. How to write a good abstract for a scientific paper or conference presentation. Indian J Psychiatry. 2011 Apr;53(2):172-5. doi: 10.4103/0019-5545.82558. PMID: 21772657; PMCID: PMC3136027 .
Share this:
- Click to print (Opens in new window)
- Click to email a link to a friend (Opens in new window)
- Click to share on WhatsApp (Opens in new window)
- Click to share on LinkedIn (Opens in new window)
- Click to share on Twitter (Opens in new window)
- Click to share on Facebook (Opens in new window)
Click here to cancel reply.
- Email * (we won't publish this)
Write a response

Navigating the dissertation process: my tips for final years
Imagine for a moment... After months of hard work and research on a topic you're passionate about, the time has finally come to click the 'Submit' button on your dissertation. You've just completed your longest project to date as part...

8 ways to beat procrastination
Whether you’re writing an assignment or revising for exams, getting started can be hard. Fortunately, there’s lots you can do to turn procrastination into action.

My takeaways on how to write a scientific report
If you’re in your dissertation writing stage or your course includes writing a lot of scientific reports, but you don’t quite know where and how to start, the Skills Centre can help you get started. I recently attended their ‘How...

Loading metrics
Open Access
Peer-reviewed
Meta-Research Article
Meta-Research Articles feature data-driven examinations of the methods, reporting, verification, and evaluation of scientific research.
See Journal Information »
Assessing the evolution of research topics in a biological field using plant science as an example
Roles Conceptualization, Data curation, Formal analysis, Funding acquisition, Investigation, Methodology, Project administration, Resources, Software, Supervision, Validation, Visualization, Writing – original draft, Writing – review & editing
* E-mail: [email protected]
Affiliations Department of Plant Biology, Michigan State University, East Lansing, Michigan, United States of America, Department of Computational Mathematics, Science, and Engineering, Michigan State University, East Lansing, Michigan, United States of America, DOE-Great Lake Bioenergy Research Center, Michigan State University, East Lansing, Michigan, United States of America
Roles Conceptualization, Investigation, Project administration, Supervision, Writing – review & editing
Affiliation Department of Plant Biology, Michigan State University, East Lansing, Michigan, United States of America
- Shin-Han Shiu,
- Melissa D. Lehti-Shiu
- Published: May 23, 2024
- https://doi.org/10.1371/journal.pbio.3002612
- Peer Review
- Reader Comments
Scientific advances due to conceptual or technological innovations can be revealed by examining how research topics have evolved. But such topical evolution is difficult to uncover and quantify because of the large body of literature and the need for expert knowledge in a wide range of areas in a field. Using plant biology as an example, we used machine learning and language models to classify plant science citations into topics representing interconnected, evolving subfields. The changes in prevalence of topical records over the last 50 years reflect shifts in major research trends and recent radiation of new topics, as well as turnover of model species and vastly different plant science research trajectories among countries. Our approaches readily summarize the topical diversity and evolution of a scientific field with hundreds of thousands of relevant papers, and they can be applied broadly to other fields.
Citation: Shiu S-H, Lehti-Shiu MD (2024) Assessing the evolution of research topics in a biological field using plant science as an example. PLoS Biol 22(5): e3002612. https://doi.org/10.1371/journal.pbio.3002612
Academic Editor: Ulrich Dirnagl, Charite Universitatsmedizin Berlin, GERMANY
Received: October 16, 2023; Accepted: April 4, 2024; Published: May 23, 2024
Copyright: © 2024 Shiu, Lehti-Shiu. This is an open access article distributed under the terms of the Creative Commons Attribution License , which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Data Availability: The plant science corpus data are available through Zenodo ( https://zenodo.org/records/10022686 ). The codes for the entire project are available through GitHub ( https://github.com/ShiuLab/plant_sci_hist ) and Zenodo ( https://doi.org/10.5281/zenodo.10894387 ).
Funding: This work was supported by the National Science Foundation (IOS-2107215 and MCB-2210431 to MDL and SHS; DGE-1828149 and IOS-2218206 to SHS), Department of Energy grant Great Lakes Bioenergy Research Center (DE-SC0018409 to SHS). The funders had no role in study design, data collection and analysis, decision to publish, or preparation of the manuscript.
Competing interests: The authors have declared that no competing interests exist.
Abbreviations: BERT, Bidirectional Encoder Representations from Transformers; br, brassinosteroid; ccTLD, country code Top Level Domain; c-Tf-Idf, class-based Tf-Idf; ChatGPT, Chat Generative Pretrained Transformer; ga, gibberellic acid; LOWESS, locally weighted scatterplot smoothing; MeSH, Medical Subject Heading; SHAP, SHapley Additive exPlanations; SJR, SCImago Journal Rank; Tf-Idf, Term frequency-Inverse document frequency; UMAP, Uniform Manifold Approximation and Projection
Introduction
The explosive growth of scientific data in recent years has been accompanied by a rapidly increasing volume of literature. These records represent a major component of our scientific knowledge and embody the history of conceptual and technological advances in various fields over time. Our ability to wade through these records is important for identifying relevant literature for specific topics, a crucial practice of any scientific pursuit [ 1 ]. Classifying the large body of literature into topics can provide a useful means to identify relevant literature. In addition, these topics offer an opportunity to assess how scientific fields have evolved and when major shifts in took place. However, such classification is challenging because the relevant articles in any topic or domain can number in the tens or hundreds of thousands, and the literature is in the form of natural language, which takes substantial effort and expertise to process [ 2 , 3 ]. In addition, even if one could digest all literature in a field, it would still be difficult to quantify such knowledge.
In the last several years, there has been a quantum leap in natural language processing approaches due to the feasibility of building complex deep learning models with highly flexible architectures [ 4 , 5 ]. The development of large language models such as Bidirectional Encoder Representations from Transformers (BERT; [ 6 ]) and Chat Generative Pretrained Transformer (ChatGPT; [ 7 ]) has enabled the analysis, generation, and modeling of natural language texts in a wide range of applications. The success of these applications is, in large part, due to the feasibility of considering how the same words are used in different contexts when modeling natural language [ 6 ]. One such application is topic modeling, the practice of establishing statistical models of semantic structures underlying a document collection. Topic modeling has been proposed for identifying scientific hot topics over time [ 1 ], for example, in synthetic biology [ 8 ], and it has also been applied to, for example, automatically identify topical scenes in images [ 9 ] and social network topics [ 10 ], discover gene programs highly correlated with cancer prognosis [ 11 ], capture “chromatin topics” that define cell-type differences [ 12 ], and investigate relationships between genetic variants and disease risk [ 13 ]. Here, we use topic modeling to ask how research topics in a scientific field have evolved and what major changes in the research trends have taken place, using plant science as an example.
Plant science corpora allow classification of major research topics
Plant science, broadly defined, is the study of photosynthetic species, their interactions with biotic/abiotic environments, and their applications. For modeling plant science topical evolution, we first identified a collection of plant science documents (i.e., corpus) using a text classification approach. To this end, we first collected over 30 million PubMed records and narrowed down candidate plant science records by searching for those with plant-related terms and taxon names (see Materials and methods ). Because there remained a substantial number of false positives (i.e., biomedical records mentioning plants in passing), a set of positive plant science examples from the 17 plant science journals with the highest numbers of plant science publications covering a wide range of subfields and a set of negative examples from journals with few candidate plant science records were used to train 4 types of text classification models (see Materials and methods ). The best text classification model performed well (F1 = 0.96, F1 of a naïve model = 0.5, perfect model = 1) where the positive and negative examples were clearly separated from each other based on prediction probability of the hold-out testing dataset (false negative rate = 2.6%, false positive rate = 5.2%, S1A and S1B Fig ). The false prediction rate for documents from the 17 plant science journals annotated with the Medical Subject Heading (MeSH) term “Plants” in NCBI was 11.7% (see Materials and methods ). The prediction probability distribution of positive instances with the MeSH term has an expected left-skew to lower values ( S1C Fig ) compared with the distributions of all positive instances ( S1A Fig ). Thus, this subset with the MeSH term is a skewed representation of articles from these 17 major plant science journals. To further benchmark the validity of the plant science records, we also conducted manual annotation of 100 records where the false positive and false negative rates were 14.6% and 10.6%, respectively (see Materials and methods ). Using 12 other plant science journals not included as positive examples as benchmarks, the false negative rate was 9.9% (see Materials and methods ). Considering the range of false prediction rate estimates with different benchmarks, we should emphasize that the model built with the top 17 plant science journals represents a substantial fraction of plant science publications but with biases. Applying the model to the candidate plant science record led to 421,658 positive predictions, hereafter referred to as “plant science records” ( S1D Fig and S1 Data ).
To better understand how the models classified plant science articles, we identified important terms from a more easily interpretable model (Term frequency-Inverse document frequency (Tf-Idf) model; F1 = 0.934) using Shapley Additive Explanations [ 14 ]; 136 terms contributed to predicting plant science records (e.g., Arabidopsis, xylem, seedling) and 138 terms contributed to non-plant science record predictions (e.g., patients, clinical, mice; Tf-Idf feature sheet, S1 Data ). Plant science records as well as PubMed articles grew exponentially from 1950 to 2020 ( Fig 1A ), highlighting the challenges of digesting the rapidly expanding literature. We used the plant science records to perform topic modeling, which consisted of 4 steps: representing each record as a BERT embedding, reducing dimensionality, clustering, and identifying the top terms by calculating class (i.e., topic)-based Tf-Idf (c-Tf-Idf; [ 15 ]). The c-Tf-Idf represents the frequency of a term in the context of how rare the term is to reduce the influence of common words. SciBERT [ 16 ] was the best model among those tested ( S2 Data ) and was used for building the final topic model, which classified 372,430 (88.3%) records into 90 topics defined by distinct combinations of terms ( S3 Data ). The topics contained 620 to 16,183 records and were named after the top 4 to 5 terms defining the topical areas ( Fig 1B and S3 Data ). For example, the top 5 terms representing the largest topic, topic 61 (16,183 records), are “qtl,” “resistance,” “wheat,” “markers,” and “traits,” which represent crop improvement studies using quantitative genetics.
- PPT PowerPoint slide
- PNG larger image
- TIFF original image
(A) Numbers of PubMed (magenta) and plant science (green) records between 1950 and 2020. (a, b, c) Coefficients of the exponential function, y = ae b . Data for the plot are in S1 Data . (B) Numbers of documents for the top 30 plant science topics. Each topic is designated by an index number (left) and the top 4–6 terms with the highest cTf-Idf values (right). Data for the plot are in S3 Data . (C) Two-dimensional representation of the relationships between plant science records generated by Uniform Manifold Approximation and Projection (UMAP, [ 17 ]) using SciBERT embeddings of plant science records. All topics panel: Different topics are assigned different colors. Outlier panel: UMAP representation of all records (gray) with outlier records in red. Blue dotted circles: areas with relatively high densities indicating topics that are below the threshold for inclusion in a topic. In the 8 UMAP representations on the right, records for example topics are in red and the remaining records in gray. Blue dotted circles indicate the relative position of topic 48.
https://doi.org/10.1371/journal.pbio.3002612.g001
Records with assigned topics clustered into distinct areas in a two-dimensional (2D) space ( Fig 1C , for all topics, see S4 Data ). The remaining 49,228 outlier records not assigned to any topic (11.7%, middle panel, Fig 1C ) have 3 potential sources. First, some outliers likely belong to unique topics but have fewer records than the threshold (>500, blue dotted circles, Fig 1C ). Second, some of the many outliers dispersed within the 2D space ( Fig 1C ) were not assigned to any single topic because they had relatively high prediction scores for multiple topics ( S2 Fig ). These likely represent studies across subdisciplines in plant science. Third, some outliers are likely interdisciplinary studies between plant science and other domains, such as chemistry, mathematics, and physics. Such connections can only be revealed if records from other domains are included in the analyses.
Topical clusters reveal closely related topics but with distinct key term usage
Related topics tend to be located close together in the 2D representation (e.g., topics 48 and 49, Fig 1C ). We further assessed intertopical relationships by determining the cosine similarities between topics using cTf-Idfs ( Figs 2A and S3 ). In this topic network, some topics are closely related and form topic clusters. For example, topics 25, 26, and 27 collectively represent a more general topic related to the field of plant development (cluster a , lower left in Fig 2A ). Other topic clusters represent studies of stress, ion transport, and heavy metals ( b ); photosynthesis, water, and UV-B ( c ); population and community biology (d); genomics, genetic mapping, and phylogenetics ( e , upper right); and enzyme biochemistry ( f , upper left in Fig 2A ).
(A) Graph depicting the degrees of similarity (edges) between topics (nodes). Between each topic pair, a cosine similarity value was calculated using the cTf-Idf values of all terms. A threshold similarity of 0.6 was applied to illustrate the most related topics. For the full matrix presented as a heatmap, see S4 Fig . The nodes are labeled with topic index numbers and the top 4–6 terms. The colors and width of the edges are defined based on cosine similarity. Example topic clusters are highlighted in yellow and labeled a through f (blue boxes). (B, C) Relationships between the cTf-Idf values (see S3 Data ) of the top terms for topics 26 and 27 (B) and for topics 25 and 27 (C) . Only terms with cTf-Idf ≥ 0.6 are labeled. Terms with cTf-Idf values beyond the x and y axis limit are indicated by pink arrows and cTf-Idf values. (D) The 2D representation in Fig 1C is partitioned into graphs for different years, and example plots for every 5-year period since 1975 are shown. Example topics discussed in the text are indicated. Blue arrows connect the areas occupied by records of example topics across time periods to indicate changes in document frequencies.
https://doi.org/10.1371/journal.pbio.3002612.g002
Topics differed in how well they were connected to each other, reflecting how general the research interests or needs are (see Materials and methods ). For example, topic 24 (stress mechanisms) is the most well connected with median cosine similarity = 0.36, potentially because researchers in many subfields consider aspects of plant stress even though it is not the focus. The least connected topics include topic 21 (clock biology, 0.12), which is surprising because of the importance of clocks in essentially all aspects of plant biology [ 18 ]. This may be attributed, in part, to the relatively recent attention in this area.
Examining topical relationships and the cTf-Idf values of terms also revealed how related topics differ. For example, topic 26 is closely related to topics 27 and 25 (cluster a on the lower left of Fig 2A ). Topics 26 and 27 both contain records of developmental process studies mainly in Arabidopsis ( Fig 2B ); however, topic 26 is focused on the impact of light, photoreceptors, and hormones such as gibberellic acids (ga) and brassinosteroids (br), whereas topic 27 is focused on flowering and floral development. Topic 25 is also focused on plant development but differs from topic 27 because it contains records of studies mainly focusing on signaling and auxin with less emphasis on Arabidopsis ( Fig 2C ). These examples also highlight the importance of using multiple top terms to represent the topics. The similarities in cTf-Idfs between topics were also useful for measuring the editorial scope (i.e., diverse, or narrow) of journals publishing plant science papers using a relative topic diversity measure (see Materials and methods ). For example, Proceedings of the National Academy of Sciences , USA has the highest diversity, while Theoretical and Applied Genetics has the lowest ( S4 Fig ). One surprise is the relatively low diversity of American Journal of Botany , which focuses on plant ecology, systematics, development, and genetics. The low diversity is likely due to the relatively larger number of cellular and molecular science records in PubMed, consistent with the identification of relatively few topical areas relevant to studies at the organismal, population, community, and ecosystem levels.
Investigation of the relative prevalence of topics over time reveals topical succession
We next asked whether relationships between topics reflect chronological progression of certain subfields. To address this, we assessed how prevalent topics were over time using dynamic topic modeling [ 19 ]. As shown in Fig 2D , there is substantial fluctuation in where the records are in the 2D space over time. For example, topic 44 (light, leaves, co, synthesis, photosynthesis) is among the topics that existed in 1975 but has diminished gradually since. In 1985, topic 39 (Agrobacterium-based transformation) became dense enough to be visualized. Additional examples include topics 79 (soil heavy metals), 42 (differential expression), and 82 (bacterial community metagenomics), which became prominent in approximately 2005, 2010, and 2020, respectively ( Fig 2D ). In addition, animating the document occupancy in the 2D space over time revealed a broad change in patterns over time: Some initially dense areas became sparse over time and a large number of topics in areas previously only loosely occupied at the turn of the century increased over time ( S5 Data ).
While the 2D representations reveal substantial details on the evolution of topics, comparison over time is challenging because the number of plant science records has grown exponentially ( Fig 1A ). To address this, the records were divided into 50 chronological bins each with approximately 8,400 records to make cross-bin comparisons feasible ( S6 Data ). We should emphasize that, because of the way the chronological bins were split, the number of records for each topic in each bin should be treated as a normalized value relative to all other topics during the same period. Examining this relative prevalence of topics across bins revealed a clear pattern of topic succession over time (one topic evolved into another) and the presence of 5 topical categories ( Fig 3 ). The topics were categorized based on their locally weighted scatterplot smoothing (LOWESS) fits and ordered according to timing of peak frequency ( S7 and S8 Data , see Materials and methods ). In Fig 3 , the relative decrease in document frequency does not mean that research output in a topic is dwindling. Because each row in the heatmap is normalized based on the minimum and maximum values within each topic, there still can be substantial research output in terms of numbers of publications even when the relative frequency is near zero. Thus, a reduced relative frequency of a topic reflects only a below-average growth rate compared with other topical areas.
(A-E) A heat map of relative topic frequency over time reveals 5 topical categories: (A) stable, (B) early, (C) transitional, (D) sigmoidal, and (E) rising. The x axis denotes different time bins with each bin containing a similar number of documents to account for the exponential growth of plant science records over time. The sizes of all bins except the first are drawn to scale based on the beginning and end dates. The y axis lists different topics denoted by the label and top 4 to 5 terms. In each cell, the prevalence of a topic in a time bin is colored according to the min-max normalized cTf-Idf values for that topic. Light blue dotted lines delineate different decades. The arrows left of a subset of topic labels indicate example relationships between topics in topic clusters. Blue boxes with labels a–f indicate topic clusters, which are the same as those in Fig 2 . Connecting lines indicate successional trends. Yellow circles/lines 1 – 3: 3 major transition patterns. The original data are in S5 Data .
https://doi.org/10.1371/journal.pbio.3002612.g003
The first topical category is a stable category with 7 topics mostly established before the 1980s that have since remained stable in terms of prevalence in the plant science records (top of Fig 3A ). These topics represent long-standing plant science research foci, including studies of plant physiology (topics 4, 58, and 81), genetics (topic 61), and medicinal plants (topic 53). The second category contains 8 topics established before the 1980s that have mostly decreased in prevalence since (the early category, Fig 3B ). Two examples are physiological and morphological studies of hormone action (topic 45, the second in the early category) and the characterization of protein, DNA, and RNA (topic 18, the second to last). Unlike other early topics, topic 78 (paleobotany and plant evolution studies, the last topic in Fig 3B ) experienced a resurgence in the early 2000s due to the development of new approaches and databases and changes in research foci [ 20 ].
The 33 topics in the third, transitional category became prominent in the 1980s, 1990s, or even 2000s but have clearly decreased in prevalence ( Fig 3C ). In some cases, the early and the transitional topics became less prevalent because of topical succession—refocusing of earlier topics led to newer ones that either show no clear sign of decrease (the sigmoidal category, Fig 3D ) or continue to increase in prevalence (the rising category, Fig 3E ). Consistent with the notion of topical succession, topics within each topic cluster ( Fig 2 ) were found across topic categories and/or were prominent at different time periods (indicated by colored lines linking topics, Fig 3 ). One example is topics in topic cluster b (connected with light green lines and arrows, compare Figs 2 and 3 ); the study of cation transport (topic 47, the third in the transitional category), prominent in the 1980s and early 1990s, is connected to 5 other topics, namely, another transitional topic 29 (cation channels and their expression) peaking in the 2000s and early 2010s, sigmoidal topics 24 and 28 (stress response, tolerance mechanisms) and 30 (heavy metal transport), which rose to prominence in mid-2000s, and the rising topic 42 (stress transcriptomic studies), which increased in prevalence in the mid-2010s.
The rise and fall of topics can be due to a combination of technological or conceptual breakthroughs, maturity of the field, funding constraints, or publicity. The study of transposable elements (topic 62) illustrates the effect of publicity; the rise in this field coincided with Barbara McClintock’s 1983 Nobel Prize but not with the publication of her studies in the 1950s [ 21 ]. The reduced prevalence in early 2000 likely occurred in part because analysis of transposons became a central component of genome sequencing and annotation studies, rather than dedicated studies. In addition, this example indicates that our approaches, while capable of capturing topical trends, cannot be used to directly infer major papers leading to the growth of a topic.
Three major topical transition patterns signify shifts in research trends
Beyond the succession of specific topics, 3 major transitions in the dynamic topic graph should be emphasized: (1) the relative decreasing trend of early topics in the late 1970s and early 1980s; (2) the rise of transitional topics in late 1980s; and (3) the relative decreasing trend of transitional topics in the late 1990s and early 2000s, which coincided with a radiation of sigmoidal and rising topics (yellow circles, Fig 3 ). The large numbers of topics involved in these transitions suggest major shifts in plant science research. In transition 1, early topics decreased in relative prevalence in the late 1970s to early 1980s, which coincided with the rise of transitional topics over the following decades (circle 1, Fig 3 ). For example, there was a shift from the study of purified proteins such as enzymes (early topic 48, S5A Fig ) to molecular genetic dissection of genes, proteins, and RNA (transitional topic 35, S5B Fig ) enabled by the wider adoption of recombinant DNA and molecular cloning technologies in late 1970s [ 22 ]. Transition 2 (circle 2, Fig 3 ) can be explained by the following breakthroughs in the late 1980s: better approaches to create transgenic plants and insertional mutants [ 23 ], more efficient creation of mutant plant libraries through chemical mutagenesis (e.g., [ 24 ]), and availability of gene reporter systems such as β-glucuronidase [ 25 ]. Because of these breakthroughs, molecular genetics studies shifted away from understanding the basic machinery to understanding the molecular underpinnings of specific processes, such as molecular mechanisms of flower and meristem development and the action of hormones such as auxin (topic 27, S5C Fig ); this type of research was discussed as a future trend in 1988 [ 26 ] and remains prevalent to this date. Another example is gene silencing (topic 12), which became a focal area of study along with the widespread use of transgenic plants [ 27 ].
Transition 3 is the most drastic: A large number of transitional, sigmoidal, and rising topics became prevalent nearly simultaneously at the turn of the century (circle 3, Fig 3 ). This period also coincides with a rapid increase in plant science citations ( Fig 1A ). The most notable breakthroughs included the availability of the first plant genome in 2000 [ 28 ], increasing ease and reduced cost of high-throughput sequencing [ 29 ], development of new mass spectrometry–based platforms for analyzing proteins [ 30 ], and advancements in microscopic and optical imaging approaches [ 31 ]. Advances in genomics and omics technology also led to an increase in stress transcriptomics studies (42, S5D Fig ) as well as studies in many other topics such as epigenetics (topic 11), noncoding RNA analysis (13), genomics and phylogenetics (80), breeding (41), genome sequencing and assembly (60), gene family analysis (23), and metagenomics (82 and 55).
In addition to the 3 major transitions across all topics, there were also transitions within topics revealed by examining the top terms for different time bins (heatmaps, S5 Fig ). Taken together, these observations demonstrate that knowledge about topical evolution can be readily revealed through topic modeling. Such knowledge is typically only available to experts in specific areas and is difficult to summarize manually, as no researcher has a command of the entire plant science literature.
Analysis of taxa studied reveals changes in research trends
Changes in research trends can also be illustrated by examining changes in the taxa being studied over time ( S9 Data ). There is a strong bias in the taxa studied, with the record dominated by research models and economically important taxa ( S6 Fig ). Flowering plants (Magnoliopsida) are found in 93% of records ( S6A Fig ), and the mustard family Brassicaceae dominates at the family level ( S6B Fig ) because the genus Arabidopsis contributes to 13% of plant science records ( Fig 4A ). When examining the prevalence of taxa being studied over time, clear patterns of turnover emerged similar to topical succession ( Figs 4B , S6C, and S6D ; Materials and methods ). Given that Arabidopsis is mentioned in more publications than other species we analyzed, we further examined the trends for Arabidopsis publications. The increase in the normalized number (i.e., relative to the entire plant science corpus) of Arabidopsis records coincided with advocacy of its use as a model system in the late 1980s [ 32 ]. While it remains a major plant model, there has been a decrease in overall Arabidopsis publications relative to all other plant science publications since 2011 (blue line, normalized total, Fig 4C ). Because the same chronological bins, each with same numbers of records, from the topic-over-time analysis ( Fig 3 ) were used, the decrease here does not mean that there were fewer Arabidopsis publications—in fact, the number of Arabidopsis papers has remained steady since 2011. This decrease means that Arabidopsis-related publications represent a relatively smaller proportion of plant science records. Interestingly, this decrease took place much earlier (approximately 2005) and was steeper in the United States (red line, Fig 4C ) than in all countries combined (blue line, Fig 4C ).
(A) Percentage of records mentioning specific genera. (B) Change in the prevalence of genera in plant science records over time. (C) Changes in the normalized numbers of all records (blue) and records from the US (red) mentioning Arabidopsis over time. The lines are LOWESS fits with fraction parameter = 0.2. (D) Topical over (red) and under (blue) representation among 5 genera with the most plant science records. LLR: log 2 likelihood ratios of each topic in each genus. Gray: topic-species combination not significantly enriched at the 5% level based on enrichment p -values adjusted for multiple testing with the Benjamini–Hochberg method [ 33 ]. The data used for plotting are in S9 Data . The statistics for all topics are in S10 Data .
https://doi.org/10.1371/journal.pbio.3002612.g004
Assuming that the normalized number of publications reflects the relative intensity of research activities, one hypothesis for the relative decrease in focus on Arabidopsis is that advances in, for example, plant transformation, genetic manipulation, and genome research have allowed the adoption of more previously nonmodel taxa. Consistent with this, there was a precipitous increase in the number of genera being published in the mid-90s to early 2000s during which approaches for plant transgenics became established [ 34 ], but the number has remained steady since then ( S7A Fig ). The decrease in the proportion of Arabidopsis papers is also negatively correlated with the timing of an increase in the number of draft genomes ( S7B Fig and S9 Data ). It is plausible that genome availability for other species may have contributed to a shift away from Arabidopsis. Strikingly, when we analyzed US National Science Foundation records, we found that the numbers of funded grants mentioning Arabidopsis ( S7C Fig ) have risen and fallen in near perfect synchrony with the normalized number of Arabidopsis publication records (red line, Fig 4C ). This finding likely illustrates the impact of funding on Arabidopsis research.
By considering both taxa information and research topics, we can identify clear differences in the topical areas preferred by researchers using different plant taxa ( Fig 4D and S10 Data ). For example, studies of auxin/light signaling, the circadian clock, and flowering tend to be carried out in Arabidopsis, while quantitative genetic studies of disease resistance tend to be done in wheat and rice, glyphosate research in soybean, and RNA virus research in tobacco. Taken together, joint analyses of topics and species revealed additional details about changes in preferred models over time, and the preferred topical areas for different taxa.
Countries differ in their contributions to plant science and topical preference
We next investigated whether there were geographical differences in topical preference among countries by inferring country information from 330,187 records (see Materials and methods ). The 10 countries with the most records account for 73% of the total, with China and the US contributing to approximately 18% each ( Fig 5A ). The exponential growth in plant science records (green line, Fig 1A ) was in large part due to the rapid rise in annual record numbers in China and India ( Fig 5B ). When we examined the publication growth rates using the top 17 plant science journals, the general patterns remained the same ( S7D Fig ). On the other hand, the US, Japan, Germany, France, and Great Britain had slower rates of growth compared with all non-top 10 countries. The rapid increase in records from China and India was accompanied by a rapid increase in metrics measuring journal impact ( Figs 5C and S8 and S9 Data ). For example, using citation score ( Fig 5C , see Materials and methods ), we found that during a 22-year period China (dark green) and India (light green) rapidly approached the global average (y = 0, yellow), whereas some of the other top 10 countries, particularly the US (red) and Japan (yellow green), showed signs of decrease ( Fig 5C ). It remains to be determined whether these geographical trends reflect changes in priority, investment, and/or interest in plant science research.
(A) Numbers of plant science records for countries with the 10 highest numbers. (B) Percentage of all records from each of the top 10 countries from 1980 to 2020. (C) Difference in citation scores from 1999 to 2020 for the top 10 countries. (D) Shown for each country is the relationship between the citation scores averaged from 1999 to 2020 and the slope of linear fit with year as the predictive variable and citation score as the response variable. The countries with >400 records and with <10% missing impact values are included. Data used for plots (A–D) are in S11 Data . (E) Correlation in topic enrichment scores between the top 10 countries. PCC, Pearson’s correlation coefficient, positive in red, negative in blue. Yellow rectangle: countries with more similar topical preferences. (F) Enrichment scores (LLR, log likelihood ratio) of selected topics among the top 10 countries. Red: overrepresentation, blue: underrepresentation. Gray: topic-country combination that is not significantly enriched at the 5% level based on enrichment p -values adjusted for multiple testing with the Benjamini–Hochberg method (for all topics and plotting data, see S12 Data ).
https://doi.org/10.1371/journal.pbio.3002612.g005
Interestingly, the relative growth/decline in citation scores over time (measured as the slope of linear fit of year versus citation score) was significantly and negatively correlated with average citation score ( Fig 5D ); i.e., countries with lower overall metrics tended to experience the strongest increase in citation scores over time. Thus, countries that did not originally have a strong influence on plant sciences now have increased impact. These patterns were also observed when using H-index or journal rank as metrics ( S8 Fig and S11 Data ) and were not due to increased publication volume, as the metrics were normalized against numbers of records from each country (see Materials and methods ). In addition, the fact that different metrics with different caveats and assumptions yielded consistent conclusions indicates the robustness of our observations. We hypothesize that this may be a consequence of the ease in scientific communication among geographically isolated research groups. It could also be because of the prevalence of online journals that are open access, which makes scientific information more readily accessible. Or it can be due to the increasing international collaboration. In any case, the causes for such regression toward the mean are not immediately clear and should be addressed in future studies.
We also assessed how the plant research foci of countries differ by comparing topical preference (i.e., the degree of enrichment of plant science records in different topics) between countries. For example, Italy and Spain cluster together (yellow rectangle, Fig 5E ) partly because of similar research focusing on allergens (topic 0) and mycotoxins (topic 54) and less emphasis on gene family (topic 23) and stress tolerance (topic 28) studies ( Fig 5F , for the fold enrichment and corrected p -values of all topics, see S12 Data ). There are substantial differences in topical focus between countries ( S9 Fig ). For example, research on new plant compounds associated with herbal medicine (topic 69) is a focus in China but not in the US, but the opposite is true for population genetics and evolution (topic 86) ( Fig 5F ). In addition to revealing how plant science research has evolved over time, topic modeling provides additional insights into differences in research foci among different countries, which are informative for science policy considerations.
In this study, topic modeling revealed clear transitions among research topics, which represent shifts in research trends in plant sciences. One limitation of our study is the bias in the PubMed-based corpus. The cellular, molecular, and physiological aspects of plant sciences are well represented, but there are many fewer records related to evolution, ecology, and systematics. Our use of titles/abstracts from the top 17 plant science journals as positive examples allowed us to identify papers we typically see in these journals, but this may have led to us missing “outlier” articles, which may be the most exciting. Another limitation is the need to assign only one topic to a record when a study is interdisciplinary and straddles multiple topics. Furthermore, a limited number of large, inherently heterogeneous topics were summarized to provide a more concise interpretation, which undoubtedly underrepresents the diversity of plant science research. Despite these limitations, dynamic topic modeling revealed changes in plant science research trends that coincide with major shifts in biological science. While we were interested in identifying conceptual advances, our approach can identify the trend but the underlying causes for such trends, particularly key records leading to the growth in certain topics, still need to be identified. It also remains to be determined which changes in research trends lead to paradigm shifts as defined by Kuhn [ 35 ].
The key terms defining the topics frequently describe various technologies (e.g., topic 38/39: transformation, 40: genome editing, 59: genetic markers, 65: mass spectrometry, 69: nuclear magnetic resonance) or are indicative of studies enabled through molecular genetics and omics technologies (e.g., topic 8/60: genome, 11: epigenetic modifications, 18: molecular biological studies of macromolecules, 13: small RNAs, 61: quantitative genetics, 82/84: metagenomics). Thus, this analysis highlights how technological innovation, particularly in the realm of omics, has contributed to a substantial number of research topics in the plant sciences, a finding that likely holds for other scientific disciplines. We also found that the pattern of topic evolution is similar to that of succession, where older topics have mostly decreased in relative prevalence but appear to have been superseded by newer ones. One example is the rise of transcriptome-related topics and the correlated, reduced focus on regulation at levels other than transcription. This raises the question of whether research driven by technology negatively impacts other areas of research where high-throughput studies remain challenging.
One observation on the overall trends in plant science research is the approximately 10-year cycle in major shifts. One hypothesis is related to not only scientific advances but also to the fashion-driven aspect of science. Nonetheless, given that there were only 3 major shifts and the sample size is small, it is difficult to speculate as to why they happened. By analyzing the country of origin, we found that China and India have been the 2 major contributors to the growth in the plant science records in the last 20 years. Our findings also show an equalizing trend in global plant science where countries without a strong plant science publication presence have had an increased impact over the last 20 years. In addition, we identified significant differences in research topics between countries reflecting potential differences in investment and priorities. Such information is important for discerning differences in research trends across countries and can be considered when making policy decisions about research directions.
Materials and methods
Collection and preprocessing of a candidate plant science corpus.
For reproducibility purposes, a random state value of 20220609 was used throughout the study. The PubMed baseline files containing citation information ( ftp://ftp.ncbi.nlm.nih.gov/pubmed/baseline/ ) were downloaded on November 11, 2021. To narrow down the records to plant science-related citations, a candidate citation was identified as having, within the titles and/or abstracts, at least one of the following words: “plant,” “plants,” “botany,” “botanical,” “planta,” and “plantarum” (and their corresponding upper case and plural forms), or plant taxon identifiers from NCBI Taxonomy ( https://www.ncbi.nlm.nih.gov/taxonomy ) or USDA PLANTS Database ( https://plants.sc.egov.usda.gov/home ). Note the search terms used here have nothing to do with the values of the keyword field in PubMed records. The taxon identifiers include all taxon names including and at taxonomic levels below “Viridiplantae” till the genus level (species names not used). This led to 51,395 search terms. After looking for the search terms, qualified entries were removed if they were duplicated, lacked titles and/or abstracts, or were corrections, errata, or withdrawn articles. This left 1,385,417 citations, which were considered the candidate plant science corpus (i.e., a collection of texts). For further analysis, the title and abstract for each citation were combined into a single entry. Text was preprocessed by lowercasing, removing stop-words (i.e., common words), removing non-alphanumeric and non-white space characters (except Greek letters, dashes, and commas), and applying lemmatization (i.e., grouping inflected forms of a word as a single word) for comparison. Because lemmatization led to truncated scientific terms, it was not included in the final preprocessing pipeline.
Definition of positive/negative examples
Upon closer examination, a large number of false positives were identified in the candidate plant science records. To further narrow down citations with a plant science focus, text classification was used to distinguish plant science and non-plant science articles (see next section). For the classification task, a negative set (i.e., non-plant science citations) was defined as entries from 7,360 journals that appeared <20 times in the filtered data (total = 43,329, journal candidate count, S1 Data ). For the positive examples (i.e., true plant science citations), 43,329 plant science citations (positive examples) were sampled from 17 established plant science journals each with >2,000 entries in the filtered dataset: “Plant physiology,” “Frontiers in plant science,” “Planta,” “The Plant journal: for cell and molecular biology,” “Journal of experimental botany,” “Plant molecular biology,” “The New phytologist,” “The Plant cell,” “Phytochemistry,” “Plant & cell physiology,” “American journal of botany,” “Annals of botany,” “BMC plant biology,” “Tree physiology,” “Molecular plant-microbe interactions: MPMI,” “Plant biology,” and “Plant biotechnology journal” (journal candidate count, S1 Data ). Plant biotechnology journal was included, but only 1,894 records remained after removal of duplicates, articles with missing info, and/or withdrawn articles. The positive and negative sets were randomly split into training and testing subsets (4:1) while maintaining a 1:1 positive-to-negative ratio.
Text classification based on Tf and Tf-Idf
Instead of using the preprocessed text as features for building classification models directly, text embeddings (i.e., representations of texts in vectors) were used as features. These embeddings were generated using 4 approaches (model summary, S1 Data ): Term-frequency (Tf), Tf-Idf [ 36 ], Word2Vec [ 37 ], and BERT [ 6 ]. The Tf- and Tf-Idf-based features were generated with CountVectorizer and TfidfVectorizer, respectively, from Scikit-Learn [ 38 ]. Different maximum features (1e4 to 1e5) and n-gram ranges (uni-, bi-, and tri-grams) were tested. The features were selected based on the p- value of chi-squared tests testing whether a feature had a higher-than-expected value among the positive or negative classes. Four different p- value thresholds were tested for feature selection. The selected features were then used to retrain vectorizers with the preprocessed training texts to generate feature values for classification. The classification model used was XGBoost [ 39 ] with 5 combinations of the following hyperparameters tested during 5-fold stratified cross-validation: min_child_weight = (1, 5, 10), gamma = (0.5, 1, 1.5, 2.5), subsample = (0.6, 0.8, 1.0), colsample_bytree = (0.6, 0.8, 1.0), and max_depth = (3, 4, 5). The rest of the hyperparameters were held constant: learning_rate = 0.2, n_estimators = 600, objective = binary:logistic. RandomizedSearchCV from Scikit-Learn was used for hyperparameter tuning and cross-validation with scoring = F1-score.
Because the Tf-Idf model had a relatively high model performance and was relatively easy to interpret (terms are frequency-based, instead of embedding-based like those generated by Word2Vec and BERT), the Tf-Idf model was selected as input to SHapley Additive exPlanations (SHAP; [ 14 ]) to assess the importance of terms. Because the Tf-Idf model was based on XGBoost, a tree-based algorithm, the TreeExplainer module in SHAP was used to determine a SHAP value for each entry in the training dataset for each Tf-Idf feature. The SHAP value indicates the degree to which a feature positively or negatively affects the underlying prediction. The importance of a Tf-Idf feature was calculated as the average SHAP value of that feature among all instances. Because a Tf-Idf feature is generated based on a specific term, the importance of the Tf-Idf feature indicates the importance of the associated term.
Text classification based on Word2Vec
The preprocessed texts were first split into train, validation, and test subsets (8:1:1). The texts in each subset were converted to 3 n-gram lists: a unigram list obtained by splitting tokens based on the space character, or bi- and tri-gram lists built with Gensim [ 40 ]. Each n-gram list of the training subset was next used to fit a Skip-gram Word2Vec model with vector_size = 300, window = 8, min_count = (5, 10, or 20), sg = 1, and epochs = 30. The Word2Vec model was used to generate word embeddings for train, validate, and test subsets. In the meantime, a tokenizer was trained with train subset unigrams using Tensorflow [ 41 ] and used to tokenize texts in each subset and turn each token into indices to use as features for training text classification models. To ensure all citations had the same number of features (500), longer texts were truncated, and shorter ones were zero-padded. A deep learning model was used to train a text classifier with an input layer the same size as the feature number, an attention layer incorporating embedding information for each feature, 2 bidirectional Long-Short-Term-Memory layers (15 units each), a dense layer (64 units), and a final, output layer with 2 units. During training, adam, accuracy, and sparse_categorical_crossentropy were used as the optimizer, evaluation metric, and loss function, respectively. The training process lasted 30 epochs with early stopping if validation loss did not improve in 5 epochs. An F1 score was calculated for each n-gram list and min_count parameter combination to select the best model (model summary, S1 Data ).
Text classification based on BERT models
Two pretrained models were used for BERT-based classification: DistilBERT (Hugging face repository [ 42 ] model name and version: distilbert-base-uncased [ 43 ]) and SciBERT (allenai/scibert-scivocab-uncased [ 16 ]). In both cases, tokenizers were retrained with the training data. BERT-based models had the following architecture: the token indices (512 values for each token) and associated masked values as input layers, pretrained BERT layer (512 × 768) excluding outputs, a 1D pooling layer (768 units), a dense layer (64 units), and an output layer (2 units). The rest of the training parameters were the same as those for Word2Vec-based models, except training lasted for 20 epochs. Cross-validation F1-scores for all models were compared and used to select the best model for each feature extraction method, hyperparameter combination, and modeling algorithm or architecture (model summary, S1 Data ). The best model was the Word2Vec-based model (min_count = 20, window = 8, ngram = 3), which was applied to the candidate plant science corpus to identify a set of plant science citations for further analysis. The candidate plant science records predicted as being in the positive class (421,658) by the model were collectively referred to as the “plant science corpus.”
Plant science record classification
In PubMed, 1,384,718 citations containing “plant” or any plant taxon names (from the phylum to genus level) were considered candidate plant science citations. To further distinguish plant science citations from those in other fields, text classification models were trained using titles and abstracts of positive examples consisting of citations from 17 plant science journals, each with >2,000 entries in PubMed, and negative examples consisting of records from journals with fewer than 20 entries in the candidate set. Among 4 models tested the best model (built with Word2Vec embeddings) had a cross validation F1 of 0.964 (random guess F1 = 0.5, perfect model F1 = 1, S1 Data ). When testing the model using 17,330 testing set citations independent from the training set, the F1 remained high at 0.961.
We also conducted another analysis attempting to use the MeSH term “Plants” as a benchmark. Records with the MeSH term “Plants” also include pharmaceutical studies of plants and plant metabolites or immunological studies of plants as allergens in journals that are not generally considered plant science journals (e.g., Acta astronautica , International journal for parasitology , Journal of chromatography ) or journals from local scientific societies (e.g., Acta pharmaceutica Hungarica , Huan jing ke xue , Izvestiia Akademii nauk . Seriia biologicheskaia ). Because we explicitly labeled papers from such journals as negative examples, we focused on 4,004 records with the “Plants” MeSH term published in the 17 plant science journals that were used as positive instances and found that 88.3% were predicted as the positive class. Thus, based on the MeSH term, there is an 11.7% false prediction rate.
We also enlisted 5 plant science colleagues (3 advanced graduate students in plant biology and genetic/genome science graduate programs, 1 postdoctoral breeder/quantitative biologist, and 1 postdoctoral biochemist/geneticist) to annotate 100 randomly selected abstracts as a reviewer suggested. Each record was annotated by 2 colleagues. Among 85 entries where the annotations are consistent between annotators, 48 were annotated as negative but with 7 predicted as positive (false positive rate = 14.6%) and 37 were annotated as positive but with 4 predicted as negative (false negative rate = 10.8%). To further benchmark the performance of the text classification model, we identified another 12 journals that focus on plant science studies to use as benchmarks: Current opinion in plant biology (number of articles: 1,806), Trends in plant science (1,723), Functional plant biology (1,717), Molecular plant pathology (1,573), Molecular plant (1,141), Journal of integrative plant biology (1,092), Journal of plant research (1,032), Physiology and molecular biology of plants (830), Nature plants (538), The plant pathology journal (443). Annual review of plant biology (417), and The plant genome (321). Among the 12,611 candidate plant science records, 11,386 were predicted as positive. Thus, there is a 9.9% false negative rate.
Global topic modeling
BERTopic [ 15 ] was used for preliminary topic modeling with n-grams = (1,2) and with an embedding initially generated by DistilBERT, SciBERT, or BioBERT (dmis-lab/biobert-base-cased-v1.2; [ 44 ]). The embedding models converted preprocessed texts to embeddings. The topics generated based on the 3 embeddings were similar ( S2 Data ). However, SciBERT-, BioBERT-, and distilBERT-based embedding models had different numbers of outlier records (268,848, 293,790, and 323,876, respectively) with topic index = −1. In addition to generating the fewest outliers, the SciBERT-based model led to the highest number of topics. Therefore, SciBERT was chosen as the embedding model for the final round of topic modeling. Modeling consisted of 3 steps. First, document embeddings were generated with SentenceTransformer [ 45 ]. Second, a clustering model to aggregate documents into clusters using hdbscan [ 46 ] was initialized with min_cluster_size = 500, metric = euclidean, cluster_selection_method = eom, min_samples = 5. Third, the embedding and the initialized hdbscan model were used in BERTopic to model topics with neighbors = 10, nr_topics = 500, ngram_range = (1,2). Using these parameters, 90 topics were identified. The initial topic assignments were conservative, and 241,567 records were considered outliers (i.e., documents not assigned to any of the 90 topics). After assessing the prediction scores of all records generated from the fitted topic models, the 95-percentile score was 0.0155. This score was used as the threshold for assigning outliers to topics: If the maximum prediction score was above the threshold and this maximum score was for topic t , then the outlier was assigned to t . After the reassignment, 49,228 records remained outliers. To assess if some of the outliers were not assigned because they could be assigned to multiple topics, the prediction scores of the records were used to put records into 100 clusters using k- means. Each cluster was then assessed to determine if the outlier records in a cluster tended to have higher prediction scores across multiple topics ( S2 Fig ).
Topics that are most and least well connected to other topics
The most well-connected topics in the network include topic 24 (stress mechanisms, median cosine similarity = 0.36), topic 42 (genes, stress, and transcriptomes, 0.34), and topic 35 (molecular genetics, 0.32, all t test p -values < 1 × 10 −22 ). The least connected topics include topic 0 (allergen research, median cosine similarity = 0.12), topic 21 (clock biology, 0.12), topic 1 (tissue culture, 0.15), and topic 69 (identification of compounds with spectroscopic methods, 0.15; all t test p- values < 1 × 10 −24 ). Topics 0, 1, and 69 are specialized topics; it is surprising that topic 21 is not as well connected as explained in the main text.
Analysis of documents based on the topic model
Topical diversity among top journals with the most plant science records
Using a relative topic diversity measure (ranging from 0 to 10), we found that there was a wide range of topical diversity among 20 journals with the largest numbers of plant science records ( S3 Fig ). The 4 journals with the highest relative topical diversities are Proceedings of the National Academy of Sciences , USA (9.6), Scientific Reports (7.1), Plant Physiology (6.7), and PLOS ONE (6.4). The high diversities are consistent with the broad, editorial scopes of these journals. The 4 journals with the lowest diversities are American Journal of Botany (1.6), Oecologia (0.7), Plant Disease (0.7), and Theoretical and Applied Genetics (0.3), which reflects their discipline-specific focus and audience of classical botanists, ecologists, plant pathologists, and specific groups of geneticists.
Dynamic topic modeling
The codes for dynamic modeling were based on _topic_over_time.py in BERTopics and modified to allow additional outputs for debugging and graphing purposes. The plant science citations were binned into 50 subsets chronologically (for timestamps of bins, see S5 Data ). Because the numbers of documents increased exponentially over time, instead of dividing them based on equal-sized time intervals, which would result in fewer records at earlier time points and introduce bias, we divided them into time bins of similar size (approximately 8,400 documents). Thus, the earlier time subsets had larger time spans compared with later time subsets. If equal-size time intervals were used, the numbers of documents between the intervals would differ greatly; the earlier time points would have many fewer records, which may introduce bias. Prior to binning the subsets, the publication dates were converted to UNIX time (timestamp) in seconds; the plant science records start in 1917-11-1 (timestamp = −1646247600.0) and end in 2021-1-1 (timestamp = 1609477201). The starting dates and corresponding timestamps for the 50 subsets including the end date are in S6 Data . The input data included the preprocessed texts, topic assignments of records from global topic modeling, and the binned timestamps of records. Three additional parameters were set for topics_over_time, namely, nr_bin = 50 (number of bins), evolution_tuning = True, and global_tuning = False. The evolution_tuning parameter specified that averaged c-Tf-Idf values for a topic be calculated in neighboring time bins to reduce fluctuation in c-Tf-Idf values. The global_tuning parameter was set to False because of the possibility that some nonexisting terms could have a high c-Tf-Idf for a time bin simply because there was a high global c-Tf-Idf value for that term.
The binning strategy based on similar document numbers per bin allowed us to increase signal particularly for publications prior to the 90s. This strategy, however, may introduce more noise for bins with smaller time durations (i.e., more recent bins) because of publication frequencies (there can be seasonal differences in the number of papers published, biased toward, e.g., the beginning of the year or the beginning of a quarter). To address this, we examined the relative frequencies of each topic over time ( S7 Data ), but we found that recent time bins had similar variances in relative frequencies as other time bins. We also moderated the impact of variation using LOWESS (10% to 30% of the data points were used for fitting the trend lines) to determine topical trends for Fig 3 . Thus, the influence of the noise introduced via our binning strategy is expected to be minimal.
Topic categories and ordering
The topics were classified into 5 categories with contrasting trends: stable, early, transitional, sigmoidal, and rising. To define which category a topic belongs to, the frequency of documents over time bins for each topic was analyzed using 3 regression methods. We first tried 2 forecasting methods: recursive autoregressor (the ForecasterAutoreg class in the skforecast package) and autoregressive integrated moving average (ARIMA implemented in the pmdarima package). In both cases, the forecasting results did not clearly follow the expected trend lines, likely due to the low numbers of data points (relative frequency values), which resulted in the need to extensively impute missing data. Thus, as a third approach, we sought to fit the trendlines with the data points using LOWESS (implemented in the statsmodels package) and applied additional criteria for assigning topics to categories. When fitting with LOWESS, 3 fraction parameters (frac, the fraction of the data used when estimating each y-value) were evaluated (0.1, 0.2, 0.3). While frac = 0.3 had the smallest errors for most topics, in situations where there were outliers, frac = 0.2 or 0.1 was chosen to minimize mean squared errors ( S7 Data ).
The topics were classified into 5 categories based on the slopes of the fitted line over time: (1) stable: topics with near 0 slopes over time; (2) early: topics with negative (<−0.5) slopes throughout (with the exception of topic 78, which declined early on but bounced back by the late 1990s); (3) transitional: early positive (>0.5) slopes followed by negative slopes at later time points; (4) sigmoidal: early positive slopes followed by zero slopes at later time points; and (5) rising: continuously positive slopes. For each topic, the LOWESS fits were also used to determine when the relative document frequency reached its peak, first reaching a threshold of 0.6 (chosen after trial and error for a range of 0.3 to 0.9), and the overall trend. The topics were then ordered based on (1) whether they belonged to the stable category or not; (2) whether the trends were decreasing, stable, or increasing; (3) the time the relative document frequency first reached 0.6; and (4) the time that the overall peak was reached ( S8 Data ).
Taxa information
To identify a taxon or taxa in all plant science records, NCBI Taxonomy taxdump datasets were downloaded from the NCBI FTP site ( https://ftp.ncbi.nlm.nih.gov/pub/taxonomy/new_taxdump/ ) on September 20, 2022. The highest-level taxon was Viridiplantae, and all its child taxa were parsed and used as queries in searches against the plant science corpus. In addition, a species-over-time analysis was conducted using the same time bins as used for dynamic topic models. The number of records in different time bins for top taxa are in the genus, family, order, and additional species level sheet in S9 Data . The degree of over-/underrepresentation of a taxon X in a research topic T was assessed using the p -value of a Fisher’s exact test for a 2 × 2 table consisting of the numbers of records in both X and T, in X but not T, in T but not X, and in neither ( S10 Data ).
For analysis of plant taxa with genome information, genome data of taxa in Viridiplantae were obtained from the NCBI Genome data-hub ( https://www.ncbi.nlm.nih.gov/data-hub/genome ) on October 28, 2022. There were 2,384 plant genome assemblies belonging to 1,231 species in 559 genera (genome assembly sheet, S9 Data ). The date of the assembly was used as a proxy for the time when a genome was sequenced. However, some species have updated assemblies and have more recent data than when the genome first became available.
Taxa being studied in the plant science records
Flowering plants (Magnoliopsida) are found in 93% of records, while most other lineages are discussed in <1% of records, with conifers and related species being exceptions (Acrogynomsopermae, 3.5%, S6A Fig ). At the family level, the mustard (Brassicaceae), grass (Poaceae), pea (Fabaceae), and nightshade (Solanaceae) families are in 51% of records ( S6B Fig ). The prominence of the mustard family in plant science research is due to the Brassica and Arabidopsis genera ( Fig 4A ). When examining the prevalence of taxa being studied over time, clear patterns of turnovers emerged ( Figs 4B , S6C, and S6D ). While the study of monocot species (Liliopsida) has remained steady, there was a significant uptick in the prevalence of eudicot (eudicotyledon) records in the late 90s ( S6C Fig ), which can be attributed to the increased number of studies in the mustard, myrtle (Myrtaceae), and mint (Lamiaceae) families among others ( S6D Fig ). At the genus level, records mentioning Gossypium (cotton), Phaseolus (bean), Hordeum (wheat), and Zea (corn), similar to the topics in the early category, were prevalent till the 1980s or 1990s but have mostly decreased in number since ( Fig 4B ). In contrast, Capsicum , Arabidopsis , Oryza , Vitus , and Solanum research has become more prevalent over the last 20 years.
Geographical information for the plant science corpus
The geographical information (country) of authors in the plant science corpus was obtained from the address (AD) fields of first authors in Medline XML records accessible through the NCBI EUtility API ( https://www.ncbi.nlm.nih.gov/books/NBK25501/ ). Because only first author affiliations are available for records published before December 2014, only the first author’s location was considered to ensure consistency between records before and after that date. Among the 421,658 records in the plant science corpus, 421,585 had Medline records and 421,276 had unique PMIDs. Among the records with unique PMIDs, 401,807 contained address fields. For each of the remaining records, the AD field content was split into tokens with a “,” delimiter, and the token likely containing geographical info (referred to as location tokens) was selected as either the last token or the second to last token if the last token contained “@” indicating the presence of an email address. Because of the inconsistency in how geographical information was described in the location tokens (e.g., country, state, city, zip code, name of institution, and different combinations of the above), the following 4 approaches were used to convert location tokens into countries.
The first approach was a brute force search where full names and alpha-3 codes of current countries (ISO 3166–1), current country subregions (ISO 3166–2), and historical country (i.e., country that no longer exists, ISO 3166–3) were used to search the address fields. To reduce false positives using alpha-3 codes, a space prior to each code was required for the match. The first approach allowed the identification of 361,242, 16,573, and 279,839 records with current country, historical country, and subregion information, respectively. The second method was the use of a heuristic based on common address field structures to identify “location strings” toward the end of address fields that likely represent countries, then the use of the Python pycountry module to confirm the presence of country information. This approach led to 329,025 records with country information. The third approach was to parse first author email addresses (90,799 records), recover top-level domain information, and use country code Top Level Domain (ccTLD) data from the ISO 3166 Wikipedia page to define countries (72,640 records). Only a subset of email addresses contains country information because some are from companies (.com), nonprofit organizations (.org), and others. Because a large number of records with address fields still did not have country information after taking the above 3 approaches, another approach was implemented to query address fields against a locally installed Nominatim server (v.4.2.3, https://github.com/mediagis/nominatim-docker ) using OpenStreetMap data from GEOFABRIK ( https://www.geofabrik.de/ ) to find locations. Initial testing indicated that the use of full address strings led to false positives, and the computing resource requirement for running the server was high. Thus, only location strings from the second approach that did not lead to country information were used as queries. Because multiple potential matches were returned for each query, the results were sorted based on their location importance values. The above steps led to an additional 72,401 records with country information.
Examining the overlap in country information between approaches revealed that brute force current country and pycountry searches were consistent 97.1% of the time. In addition, both approaches had high consistency with the email-based approach (92.4% and 93.9%). However, brute force subregion and Nominatim-based predictions had the lowest consistencies with the above 3 approaches (39.8% to 47.9%) and each other. Thus, a record’s country information was finalized if the information was consistent between any 2 approaches, except between the brute force subregion and Nominatim searches. This led to 330,328 records with country information.
Topical and country impact metrics
To determine annual country impact, impact scores were determined in the same way as that for annual topical impact, except that values for different countries were calculated instead of topics ( S8 Data ).
Topical preferences by country
To determine topical preference for a country C , a 2 × 2 table was established with the number of records in topic T from C , the number of records in T but not from C , the number of non- T records from C , and the number of non- T records not from C . A Fisher’s exact test was performed for each T and C combination, and the resulting p -values were corrected for multiple testing with the Bejamini–Hochberg method (see S12 Data ). The preference of T in C was defined as the degree of enrichment calculated as log likelihood ratio of values in the 2 × 2 table. Topic 5 was excluded because >50% of the countries did not have records for this topic.
The top 10 countries could be classified into a China–India cluster, an Italy–Spain cluster, and remaining countries (yellow rectangles, Fig 5E ). The clustering of Italy and Spain is partly due to similar research focusing on allergens (topic 0) and mycotoxins (topic 54) and less emphasis on gene family (topic 23) and stress tolerance (topic 28) studies ( Figs 5F and S9 ). There are also substantial differences in topical focus between countries. For example, plant science records from China tend to be enriched in hyperspectral imaging and modeling (topic 9), gene family studies (topic 23), stress biology (topic 28), and research on new plant compounds associated with herbal medicine (topic 69), but less emphasis on population genetics and evolution (topic 86, Fig 5F ). In the US, there is a strong focus on insect pest resistance (topic 75), climate, community, and diversity (topic 83), and population genetics and evolution but less focus on new plant compounds. In summary, in addition to revealing how plant science research has evolved over time, topic modeling provides additional insights into differences in research foci among different countries.
Supporting information
S1 fig. plant science record classification model performance..
(A–C) Distributions of prediction probabilities (y_prob) of (A) positive instances (plant science records), (B) negative instances (non-plant science records), and (C) positive instances with the Medical Subject Heading “Plants” (ID = D010944). The data are color coded in blue and orange if they are correctly and incorrectly predicted, respectively. The lower subfigures contain log10-transformed x axes for the same distributions as the top subfigure for better visualization of incorrect predictions. (D) Prediction probability distribution for candidate plant science records. Prediction probabilities plotted here are available in S13 Data .
https://doi.org/10.1371/journal.pbio.3002612.s001
S2 Fig. Relationships between outlier clusters and the 90 topics.
(A) Heatmap demonstrating that some outlier clusters tend to have high prediction scores for multiple topics. Each cell shows the average prediction score of a topic for records in an outlier cluster. (B) Size of outlier clusters.
https://doi.org/10.1371/journal.pbio.3002612.s002
S3 Fig. Cosine similarities between topics.
(A) Heatmap showing cosine similarities between topic pairs. Top-left: hierarchical clustering of the cosine similarity matrix using the Ward algorithm. The branches are colored to indicate groups of related topics. (B) Topic labels and names. The topic ordering was based on hierarchical clustering of topics. Colored rectangles: neighboring topics with >0.5 cosine similarities.
https://doi.org/10.1371/journal.pbio.3002612.s003
S4 Fig. Relative topical diversity for 20 journals.
The 20 journals with the most plant science records are shown. The journal names were taken from the journal list in PubMed ( https://www.nlm.nih.gov/bsd/serfile_addedinfo.html ).
https://doi.org/10.1371/journal.pbio.3002612.s004
S5 Fig. Topical frequency and top terms during different time periods.
(A-D) Different patterns of topical frequency distributions for example topics (A) 48, (B) 35, (C) 27, and (D) 42. For each topic, the top graph shows the frequency of topical records in each time bin, which are the same as those in Fig 3 (green line), and the end date for each bin is indicated. The heatmap below each line plot depicts whether a term is among the top terms in a time bin (yellow) or not (blue). Blue dotted lines delineate different decades (see S5 Data for the original frequencies, S6 Data for the LOWESS fitted frequencies and the top terms for different topics/time bins).
https://doi.org/10.1371/journal.pbio.3002612.s005
S6 Fig. Prevalence of records mentioning different taxonomic groups in Viridiplantae.
(A, B) Percentage of records mentioning specific taxa at the ( A) major lineage and (B) family levels. (C, D) The prevalence of taxon mentions over time at the (C) major lineage and (E) family levels. The data used for plotting are available in S9 Data .
https://doi.org/10.1371/journal.pbio.3002612.s006
S7 Fig. Changes over time.
(A) Number of genera being mentioned in plant science records during different time bins (the date indicates the end date of that bin, exclusive). (B) Numbers of genera (blue) and organisms (salmon) with draft genomes available from National Center of Biotechnology Information in different years. (C) Percentage of US National Science Foundation (NSF) grants mentioning the genus Arabidopsis over time with peak percentage and year indicated. The data for (A–C) are in S9 Data . (D) Number of plant science records in the top 17 plant science journals from the USA (red), Great Britain (GBR) (orange), India (IND) (light green), and China (CHN) (dark green) normalized against the total numbers of publications of each country over time in these 17 journals. The data used for plotting can be found in S11 Data .
https://doi.org/10.1371/journal.pbio.3002612.s007
S8 Fig. Change in country impact on plant science over time.
(A, B) Difference in 2 impact metrics from 1999 to 2020 for the 10 countries with the highest number of plant science records. (A) H-index. (B) SCImago Journal Rank (SJR). (C, D) Plots show the relationships between the impact metrics (H-index in (C) , SJR in (D) ) averaged from 1999 to 2020 and the slopes of linear fits with years as the predictive variable and impact metric as the response variable for different countries (A3 country codes shown). The countries with >400 records and with <10% missing impact values are included. The data used for plotting can be found in S11 Data .
https://doi.org/10.1371/journal.pbio.3002612.s008
S9 Fig. Country topical preference.
Enrichment scores (LLR, log likelihood ratio) of topics for each of the top 10 countries. Red: overrepresentation, blue: underrepresentation. The data for plotting can be found in S12 Data .
https://doi.org/10.1371/journal.pbio.3002612.s009
S1 Data. Summary of source journals for plant science records, prediction models, and top Tf-Idf features.
Sheet–Candidate plant sci record j counts: Number of records from each journal in the candidate plant science corpus (before classification). Sheet—Plant sci record j count: Number of records from each journal in the plant science corpus (after classification). Sheet–Model summary: Model type, text used (txt_flag), and model parameters used. Sheet—Model performance: Performance of different model and parameter combinations on the validation data set. Sheet–Tf-Idf features: The average SHAP values of Tf-Idf (Term frequency-Inverse document frequency) features associated with different terms. Sheet–PubMed number per year: The data for PubMed records in Fig 1A . Sheet–Plant sci record num per yr: The data for the plant science records in Fig 1A .
https://doi.org/10.1371/journal.pbio.3002612.s010
S2 Data. Numbers of records in topics identified from preliminary topic models.
Sheet–Topics generated with a model based on BioBERT embeddings. Sheet–Topics generated with a model based on distilBERT embeddings. Sheet–Topics generated with a model based on SciBERT embeddings.
https://doi.org/10.1371/journal.pbio.3002612.s011
S3 Data. Final topic model labels and top terms for topics.
Sheet–Topic label: The topic index and top 10 terms with the highest cTf-Idf values. Sheets– 0 to 89: The top 50 terms and their c-Tf-Idf values for topics 0 to 89.
https://doi.org/10.1371/journal.pbio.3002612.s012
S4 Data. UMAP representations of different topics.
For a topic T , records in the UMAP graph are colored red and records not in T are colored gray.
https://doi.org/10.1371/journal.pbio.3002612.s013
S5 Data. Temporal relationships between published documents projected onto 2D space.
The 2D embedding generated with UMAP was used to plot document relationships for each year. The plots from 1975 to 2020 were compiled into an animation.
https://doi.org/10.1371/journal.pbio.3002612.s014
S6 Data. Timestamps and dates for dynamic topic modeling.
Sheet–bin_timestamp: Columns are: (1) order index; (2) bin_idx–relative positions of bin labels; (3) bin_timestamp–UNIX time in seconds; and (4) bin_date–month/day/year. Sheet–Topic frequency per timestamp: The number of documents in each time bin for each topic. Sheets–LOWESS fit 0.1/0.2/0.3: Topic frequency per timestamp fitted with the fraction parameter of 0.1, 0.2, or 0.3. Sheet—Topic top terms: The top 5 terms for each topic in each time bin.
https://doi.org/10.1371/journal.pbio.3002612.s015
S7 Data. Locally weighted scatterplot smoothing (LOWESS) of topical document frequencies over time.
There are 90 scatter plots, one for each topic, where the x axis is time, and the y axis is the document frequency (blue dots). The LOWESS fit is shown as orange points connected with a green line. The category a topic belongs to and its order in Fig 3 are labeled on the top left corner. The data used for plotting are in S6 Data .
https://doi.org/10.1371/journal.pbio.3002612.s016
S8 Data. The 4 criteria used for sorting topics.
Peak: the time when the LOWESS fit of the frequencies of a topic reaches maximum. 1st_reach_thr: the time when the LOWESS fit first reaches a threshold of 60% maximal frequency (peak value). Trend: upward (1), no change (0), or downward (−1). Stable: whether a topic belongs to the stable category (1) or not (0).
https://doi.org/10.1371/journal.pbio.3002612.s017
S9 Data. Change in taxon record numbers and genome assemblies available over time.
Sheet–Genus: Number of records mentioning a genus during different time periods (in Unix timestamp) for the top 100 genera. Sheet–Genus: Number of records mentioning a family during different time periods (in Unix timestamp) for the top 100 families. Sheet–Genus: Number of records mentioning an order during different time periods (in Unix timestamp) for the top 20 orders. Sheet–Species levels: Number of records mentioning 12 selected taxonomic levels higher than the order level during different time periods (in Unix timestamp). Sheet–Genome assembly: Plant genome assemblies available from NCBI as of October 28, 2022. Sheet–Arabidopsis NSF: Absolute and normalized numbers of US National Science Foundation funded proposals mentioning Arabidopsis in proposal titles and/or abstracts.
https://doi.org/10.1371/journal.pbio.3002612.s018
S10 Data. Taxon topical preference.
Sheet– 5 genera LLR: The log likelihood ratio of each topic in each of the top 5 genera with the highest numbers of plant science records. Sheets– 5 genera: For each genus, the columns are: (1) topic; (2) the Fisher’s exact test p -value (Pvalue); (3–6) numbers of records in topic T and in genus X (n_inT_inX), in T but not in X (n_inT_niX), not in T but in X (n_niT_inX), and not in T and X (n_niT_niX) that were used to construct 2 × 2 tables for the tests; and (7) the log likelihood ratio generated with the 2 × 2 tables. Sheet–corrected p -value: The 4 values for generating LLRs were used to conduct Fisher’s exact test. The p -values obtained for each country were corrected for multiple testing.
https://doi.org/10.1371/journal.pbio.3002612.s019
S11 Data. Impact metrics of countries in different years.
Sheet–country_top25_year_count: number of total publications and publications per year from the top 25 countries with the most plant science records. Sheet—country_top25_year_top17j: number of total publications and publications per year from the top 25 countries with the highest numbers of plant science records in the 17 plant science journals used as positive examples. Sheet–prank: Journal percentile rank scores for countries (3-letter country codes following https://www.iban.com/country-codes ) in different years from 1999 to 2020. Sheet–sjr: Scimago Journal rank scores. Sheet–hidx: H-Index scores. Sheet–cite: Citation scores.
https://doi.org/10.1371/journal.pbio.3002612.s020
S12 Data. Topical enrichment for the top 10 countries with the highest numbers of plant science publications.
Sheet—Log likelihood ratio: For each country C and topic T, it is defined as log((a/b)/(c/d)) where a is the number of papers from C in T, b is the number from C but not in T, c is the number not from C but in T, d is the number not from C and not in T. Sheet: corrected p -value: The 4 values, a, b, c, and d, were used to conduct Fisher’s exact test. The p -values obtained for each country were corrected for multiple testing.
https://doi.org/10.1371/journal.pbio.3002612.s021
S13 Data. Text classification prediction probabilities.
This compressed file contains the PubMed ID (PMID) and the prediction probabilities (y_pred) of testing data with both positive and negative examples (pred_prob_testing), plant science candidate records with the MeSH term “Plants” (pred_prob_candidates_with_mesh), and all plant science candidate records (pred_prob_candidates_all). The prediction probability was generated using the Word2Vec text classification models for distinguishing positive (plant science) and negative (non-plant science) records.
https://doi.org/10.1371/journal.pbio.3002612.s022
Acknowledgments
We thank Maarten Grootendorst for discussions on topic modeling. We also thank Stacey Harmer, Eva Farre, Ning Jiang, and Robert Last for discussion on their respective research fields and input on how to improve this study and Rudiger Simon for the suggestion to examine differences between countries. We also thank Mae Milton, Christina King, Edmond Anderson, Jingyao Tang, Brianna Brown, Kenia Segura Abá, Eleanor Siler, Thilanka Ranaweera, Huan Chen, Rajneesh Singhal, Paulo Izquierdo, Jyothi Kumar, Daniel Shiu, Elliott Shiu, and Wiggler Catt for their good ideas, personal and professional support, collegiality, fun at parties, as well as the trouble they have caused, which helped us improve as researchers, teachers, mentors, and parents.
- View Article
- PubMed/NCBI
- Google Scholar
- 2. Blei DM, Lafferty JD. Topic Models. In: Srivastava A, Sahami M, editors. Text Mining. Cambridge: Chapman and Hall/CRC; 2009. pp. 71–93.
- 7. ChatGPT. [cited 2023 Aug 25]. Available from: https://chat.openai.com
- 9. Fei-Fei L, Perona P. A Bayesian hierarchical model for learning natural scene categories. 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05); 2005. pp. 524–531 vol. 2. https://doi.org/10.1109/CVPR.2005.16
- 19. Blei DM, Lafferty JD. Dynamic topic models. Proceedings of the 23rd International Conference on Machine learning. New York, NY, USA: Association for Computing Machinery; 2006. pp. 113–120. https://doi.org/10.1145/1143844.1143859
- 35. Kuhn T. The Structure of Scientific Revolution. Chicago: University of Chicago Press; 1962.
- 36. CiteSeer | Proceedings of the second international conference on Autonomous agents. [cited 2023 Aug 23]. Available from: https://dl.acm.org/doi/10.1145/280765.280786
- 39. Chen T, Guestrin C. XGBoost: A Scalable Tree Boosting System. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York, NY, USA: ACM; 2016. pp. 785–794. https://doi.org/10.1145/2939672.2939785
- 40. Řehůřek R, Sojka P. Software Framework for Topic Modelling with Large Corpora. Proceedings of the LREC 2010 Workshop on New Challenges for NLP Frameworks. Valletta, Malta: ELRA; 2010. pp. 45–50.
- 42. Hugging Face–The AI community building the future. 2023 Aug 19 [cited 2023 Aug 25]. Available from: https://huggingface.co/
Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
- View all journals
- My Account Login
- Explore content
- About the journal
- Publish with us
- Sign up for alerts
- Open access
- Published: 25 May 2024
Exploring the “gene–metabolite” network of ischemic stroke with blood stasis and toxin syndrome by integrated transcriptomics and metabolomics strategy
- Yue Liu 1 na1 ,
- Wenqiang Cui 1 , 3 na1 ,
- Hongxi Liu 1 na1 ,
- Mingjiang Yao 1 , 2 ,
- Wei Shen 1 ,
- Lina Miao 1 ,
- Jingjing Wei 1 ,
- Xiao Liang 1 &
- Yunling Zhang 1
Scientific Reports volume 14 , Article number: 11947 ( 2024 ) Cite this article
62 Accesses
Metrics details
- Diseases of the nervous system
A research model combining a disease and syndrome can provide new ideas for the treatment of ischemic stroke. In the field of traditional Chinese medicine, blood stasis and toxin (BST) syndrome is considered an important syndrome seen in patients with ischemic stroke (IS). However, the biological basis of IS-BST syndrome is currently not well understood. Therefore, this study aimed to explore the biological mechanism of IS-BST syndrome. This study is divided into two parts: (1) establishment of an animal model of ischemic stroke disease and an animal model of BST syndrome in ischemic stroke; (2) use of omics methods to identify differentially expressed genes and metabolites in the models. We used middle cerebral artery occlusion (MCAO) surgery to establish the disease model, and utilized carrageenan combined with active dry yeast and MCAO surgery to construct the IS-BST syndrome model. Next, we used transcriptomics and metabolomics methods to explore the differential genes and metabolites in the disease model and IS-BST syndrome model. It is found that the IS-BST syndrome model exhibited more prominent characteristics of IS disease and syndrome features. Both the disease model and the IS-BST syndrome model share some common biological processes, such as thrombus formation, inflammatory response, purine metabolism, sphingolipid metabolism, and so on. Results of the “gene–metabolite” network revealed that the IS-BST syndrome model exhibited more pronounced features of complement-coagulation cascade reactions and amino acid metabolism disorders. Additionally, the “F2 (thrombin)–NMDAR/glutamate” pathway was coupled with the formation process of the blood stasis and toxin syndrome. This study reveals the intricate mechanism of IS-BST syndrome, offering a successful model for investigating the combination of disease and syndrome.
Similar content being viewed by others

Pinocembrin attenuates hemorrhagic transformation after delayed t-PA treatment in thromboembolic stroke rats by regulating endogenous metabolites

FSAP aggravated endothelial dysfunction and neurological deficits in acute ischemic stroke due to large vessel occlusion

Analysis and identification of oxidative stress-ferroptosis related biomarkers in ischemic stroke
Introduction.
Stroke, an illness characterized by a high rate of morbidity, mortality, and disability, is the second leading cause of death globally 1 . Ischemic Stroke (IS) accounts for 87% of all stroke incidences and is the outcome of blood flow disruption caused by thrombotic and embolic events 2 , 3 . The recombinant tissue plasminogen activator (rt-PA) is currently the only approved medical therapy for IS. However, its clinical applicability is limited to only a small proportion of stroke patients by the narrow time window in which it can be administered 4 , 5 . As a result, the development of novel therapeutic drugs or combination therapies for IS treatment is imperative. With few therapeutic options available, patients and healthcare workers are increasingly embracing traditional Chinese medicine (TCM), which has a unique theoretical system characterized by a holistic concept and syndrome differentiation and treatment principles 6 . According to research, combining TCM and Western medication is effective in symptom relief, neurological healing, and enhancing IS patients’ Quality of Life (QoL) 7 , 8 .
The TCM concept is based on the fact that different stages of disease occurrence and development could present varying symptoms and signs. Syndrome ( ZHENG in Chinese) comprises symptoms and signs that reflect the essence of a particular stage or type of disease. The various stages or types of syndromes intertwine and overlap, making up the entirety of the disease process. Developing a research model that integrates the “disease” concept in Western medicine with the “syndrome” concept in TCM theory is one of the future directions in Chinese integrative medicine. This approach aims to enhance our understanding of complex health conditions by harmonizing the perspectives of the two medical systems 9 . Blood stasis is an essential pathogenesis in TCM theory and clinical practice of IS, and the blood stasis syndrome ( Xueyu Zheng ) is the most common type of IS 10 . However, IS a dangerous condition that often progresses rapidly, and a single blood stasis theory may not comprehensively explain its complex pathogenic factors and processes 11 . The clinical IS manifestations caused by a sudden blood flow disruption are highly similar to those of diseases precipitated by ‘toxin’ in TCM. Illnesses caused by ‘toxin’ are often sudden and could even be fatal 12 . According to TCM, ‘toxins’ are formed by the accumulation and transformation of other pathogenic elements. Since blood stasis lasts for a long time, it could breed toxins. As a result, current IS practices stress the critical involvement of “blood stasis and toxin interaction” in its occurrence 13 . However, the biological mechanism underlying the Blood Stasis and Toxin (BST) syndrome remains unclear. Therefore, elucidating the biological basis of the IS-BST syndrome will undoubtedly promote advancements in the IS treatment methodology ( Supplementary Information ).
The Disease-Syndrome (DS) combination modeling is a crucial aspect of biomedical research 14 . According to the TCM basic theory, blood stasis could breed toxin, which in turn can consume body fluid, increasing blood viscosity and leading to blood stasis ultimately. Blood stasis and toxin accumulate in the body, leading to the occurrence of diseases. Modern medical research often explains this process as microcirculation disorder, abnormal hemorheology, enhanced platelet aggregation, inflammatory reactions, etc. Carrageenan (Ca) is considered to damage vascular endothelial cells and cause thrombosis, and is often used to prepare rodent thrombosis models 15 , 16 . Lipopolysaccharides (LPS) and active dry yeast (Yeast) acting on the body can induce the production of endogenous inflammatory factors and toxic substances, and are often used as tools in simulating the TCM concept of “toxin”. Our previous research utilized Ca to simulate the pathogenic factor of blood stasis, and used LPS and Yeast to simulate toxic pathogenic factors. We systematically compared BST models constructed using these three methods: simple Ca, Ca combined with LPS, and Ca combined with Yeast. We comprehensively evaluated syndrome characteristics, tail blood flow perfusion, whole blood viscosity, plasma viscosity, platelet aggregation rate, and plasma inflammatory factors, and ultimately found that the combination of Ca and Yeast models can present more stable BST syndrome characteristics. The BST model, established through the combination of Ca and Yeast, exhibited fever, a black tail phenomenon, reduced tail blood perfusion, elevated whole blood and plasma viscosity, increased platelet aggregation rate, and raised levels of the plasma inflammatory factor IL-6 17 . Based on these results, the present work aimed to establish a comprehensive animal model incorporating both the IS pathological characteristics and the BST syndrome characteristics. Specifically, we aim to create a fundamental tool for further studying the essence of IS and pharmacological mechanisms of Chinese herbal medicine. In other words, for a better understanding, it is important to conduct IS or syndrome-guided medication research on a mature DS combination model. However, diseases and syndromes are holistic concepts, and it is difficult to comprehensively describe the combination of diseases and syndromes using limited model evaluation indicators. As a solution to this drawback, omics technology has played an increasingly important role in life sciences in recent years, allowing the complexity of biological processes to be explained from multiple perspectives 18 . The application of “omics” in TCM research has attracted widespread attention, offering a technical platform for exploring the essence of the DS combination 19 , 20 , 21 .
Herein, we created a rat model incorporating both IS and the BST syndrome and designated it as the DS model. Transcriptomic and metabolomic approaches were used to investigate the biological basis of this model, yielding insights into the mechanisms underlying the IS-BST syndrome (Fig. 1 ). In addition to providing a scientific basis for TCM complexity, this study may discover new diagnostic biomarkers of the IS-BST syndrome, offering potential therapeutic targets for IS treatment.

The flowchart of modeling methods and transcriptomics and metabolomics research.
Materials and methods
Experimental animals.
Fourty-five male Specific Pathogen-Free (SPF) Sprague Dawley (SD) rats (weight = 230 ± 10 g) were purchased from Beijing Weitong Lihua Co., Ltd. [Beijing, China; Laboratory animal certificate number: SYXK (jing), 2018-0018]. These animals were housed in a controlled environment of 16 °C ± 2 °C and humidity of 55% ± 5% under a 12-h light/dark cycle and were allowed ad libitum access to food and water throughout the experiment. The Experimental Ethics Committee of Xiyuan Hospital ethically reviewed and approved this study’s research protocol.
Reagents and materials
Carrageenan was supplied by Shanghai Macklin Biochemical Co., Ltd. (Shanghai, China, Batch No: C14408398). Active dry yeast was purchased from Angel Yeast Co., Ltd. (Yichang, China; Batch No: HY2009R). The rat Interleukin-6 (IL-6) Enzyme-Linked Immunosorbent Assay (ELISA) kit was acquired from Cohesion Biosciences. (UK; Batch No: CEK1619). Nylon suture for Middle Cerebral Artery Occlusion (MCAO) surgery was purchased from Hebei Tiannong Biotechnology Co., Ltd. (Shijiazhuang, China; Batch No: 20210630).
Modeling and evaluation methods of disease and syndrome animal models
Modeling methods.
After 3 days of adaptive feeding, the rats were randomly divided into three groups (n = 15): normal control group (NC group), the disease model group (Disease group) and the disease-syndrome model group (DS group).
The DS group was intraperitoneally injected with 10 mg·kg −1 of carrageenan on the first day of modeling. On the second day, the Disease and DS groups underwent MCAO surgery. Notably, the DS group was subcutaneously injected with 2 g·kg −1 of active dry yeast into the back immediately after inserting the nylon suture into the middle cerebral artery. On the other hand, the NC group was fed normally and received no treatment.
The modified Longa method was used to induce MCAO surgery 22 . The animals in the Disease and DS groups were weighed and anesthetized with pentobarbital sodium (40 mg·kg −1 ) after 12 h of fasting (water allowed). Subsequently, the anesthetized rats were fixed on the operating table, and the right Common Carotid Artery (CCA) and the right External Carotid Artery (ECA) were separated through a longitudinal incision in the middle of the neck and ligated near the cardiac end. A loose knot was then tied approximately 0.5 cm above the ligature. The Internal Carotid Artery (ICA) was clamped with an arterial clamp, and a small incision was made between the sliding and dead nodes of the CCA. The ICA artery clamp was tied off once the nylon suture was inserted and made contact with the CCA bifurcation. The suture entered the ICA from the CCA up until it reached the initial area of the anterior cerebral artery. The insertion was stopped when a small amount of resistance was felt from the incision, at approximately 18 mm. After 1.5 h of ischemia, the suture was removed from the ICA to the CCA, followed by 22.5 h of reperfusion.
Model evaluation indicators and methods
Model evaluation was performed as follows:
General observations: Mental status, diet, movement, and body hair glossiness of three animal groups were observed and recorded. The characteristic manifestations of the rat syndromes were also observed.
Evaluation of neurological deficits: A validated five-point scale was used to quantify the neurological deficit scores for all rats at 24 h postoperatively 23 . Specifically, a rat with no neurological deficit symptoms received a score of 0, a rat failing to completely stretch the left fore paw received a score of 1, a rat circling to the left received a score of 2, a rat falling to the left or rolling on the ground received a score of 3, and a rat showing no spontaneous activity with consciousness disorder received a score of 4.
Tail blood flow perfusion detection: The PeriCam PSI system (Perimed, Sweden) was used to detect blood perfusion in the rats’ tail tips. We focused the cursor on the 1 cm point at the tip of the rat tail, and then observed and recorded the tail blood perfusion. The laser blood perfusion speckle image was generated, and then the average blood perfusion of the tail tip of each group of rats was analyzed using PIMSoft software along with the PeriCam PSI system.
Detection of Whole Blood Viscosity (WBV), Plasma Viscosity (PV), and platelet Aggregation Rate (AR): Blood samples were extracted from the abdominal aorta of rats. The blood was then collected into one heparin anticoagulant tube and one sodium citrate anticoagulant tube. Subsequently, WBV, PV, and platelet AR were detected in rats using a fully automatic hemorheological analyzer (Beijing Succeeder Technology Inc., China) and a PL-12 platelet function analyzer (SINNOWA Medical Science and Technology Co., Ltd., China).
Measurement of the cerebral infarction area: We performed 2,3,5-Triphenyltetrazolium Chloride (TTC, Sigma, USA) staining to visualize the ischemic infarction area. All rat brains were sliced into 2-mm-thick coronal sections before incubating each slice in a 0.1% TTC solution at 37 °C for 30 min. The slices were then fixed in 4% paraformaldehyde. The infarction area was quantified using Image J software.
Hematoxylin–eosin staining (HE): Brain samples were swiftly extracted from all rats, followed by overnight fixation in 4% paraformaldehyde. Subsequently, the brains were dehydrated using graded alcohol and encased in paraffin wax. The 5 μm thick-paraffin-embedded brain tissue sections were then processed with the HE kit to observe the neuronal pathological changes.
Enzyme-Linked Immunosorbent Assay (ELISA): Cortical tissue samples were extracted from the rats’ ischemic hemisphere and the corresponding side in the NC group. The tissue samples were then incubated with an appropriate lysis buffer volume and mechanically processed using a cold grinder. The mixture was allowed to settle before obtaining the supernatant by centrifuging it at 3000 rpm for 10 min at 4 °C. The interleukin-6 (IL-6) expression level in the rat brain tissue was determined using an ELISA kit per the recommended protocol.
Research on the biological basis of the disease-syndrome combination model through integrated transcriptomics and metabolomics analysis
Based on the established model, transcriptomic and metabolomic analyses were performed on the brain tissues of the three groups of rats to explore the biological mechanisms of the DS model.
RNA-seq-based transcriptomic study
Rna extraction, library construction and sequencing.
Total RNA was extracted from the ischemic cortical tissue of rats using the Trizol Reagent (Invitrogen Life Technologies). Four samples were processed per group. A NanoDrop spectrophotometer (Thermo Scientific) was used to assess the concentration, quality, and integrity of the extracted RNAs. Three micrograms of RNA were used as input material for RNA sample preparations.
The RNA library was completed by Shanghai Personal Biotechnology Co. Ltd. A total RNA of ≥ 1 μg was selected, and cDNA was synthesized using the NEBNext Ultra II RNA Library Prep Kit (Illumina). The AMPure XP beads were used to screen cDNA fragments of around 400–500 bp, perform PCR amplification, and purify the PCR product, resulting in a library. Sequencing was performed using the NovaSeq 6000 platform (Illumina) after completing the library quality inspection.
Differential gene expression analysis
The image file was obtained after sequencing the sample on the machine, and the sequencing platform generated the original FASTQ data (Raw data). Quality checks were performed on raw data using FastQC v0.11.8. Reads that met the quality control (QC) standards for the rat reference genome were mapped using the HISAT2 aligner v2.0.5. The read count of the original expression level of each gene was obtained using HTSeq. Fragments Per Kilobase of transcript per Million fragments mapped (FPKM) were used to normalize expression levels to ensure comparability of gene expression levels between different genes and samples. Transcriptomic analysis was performed through Principal Components Analysis (PCA). Differential Gene (DG) expression analysis was performed using the DESeq2 package, with P < 0.05 and |log2FoldChange| > 1 as the screening conditions. Gene ontology (GO) and Kyoto Encyclopedia of Genes and Genome (KEGG) analyses of DGs were performed using the Database for Annotation Visualization and Integrated Discovery (DAVID).
Untargeted metabolomic study
Sample pretreatment.
Sample preparation and liquid chromatography—tandem mass spectrometry (LC–MS/MS) detection were completed by Shanghai Personal Biotechnology Co. Ltd. Eight ischemic cortical tissue samples per group were thawed gradually at 4 °C. Subsequently, 1 mL of precooling methyl alcohol/acetonitrile/water (2:2:1, v/v) was added, and the mixture was sufficiently vortexed. After 30 min of low-temperature ultrasonic breakdown, the samples were centrifuged at 14,000× g for 20 min at 4 °C to precipitate the protein. The supernatants were collected, vacuum-dried, and kept at − 80 °C, awaiting further experiments. The material was then resolved in 100 μL acetonitrile/water (1:1, v/v), sufficiently vortexed, and centrifuged at 14,000 rpm, for 15 min at 4 °C. Following that, the supernatants were subjected to LC–MS/MS analysis.
LC–MS/MS analysis
Chromatographic separation was performed using an ACQUITY UPLC BEH C18 column (100 mm × 2.1 mm, 1.7 μm, Waters, USA) with a column temperature of 40 °C and a flow rate of 0.3 mL/min. The mobile phase A consisted of water with 0.1% formic acid, while mobile phase B was acetonitrile. The metabolites were eluted using the following gradient: 0–0.5 min, 5%B; 0.5–1.0 min, 5%B; 1.0–9.0 min, 5–100%B; 9.0–12.0 min, 100%B; 12.0–15.0 min, 5%B. The sample injection volume for each sample was 5 μL. Throughout the analysis, samples were kept in an autosampler at 4 °C. To avoid any impact from instrument signal fluctuations, samples were analyzed in random order. Quality control (QC) samples were inserted after each group of samples in the sample queue to monitor and assess system stability and the reliability of experimental data.
The MS conditions were as follows: Ion source: electrospray ionization (ESI); Samples were detected in both ESI positive and negative modes. Mass spectrum parameters: Ion source gas1 (Gas1): 60; Ion source gas2 (Gas2): 60; Curtain gas: 30; Source temperature: 320 °C; Spray Voltage (V): 3500 (positive ion), − 3500 (negative ion). In MS only acquisition, the instrument was set to acquire over the m/z range 60–1000 Da, product ion scan m/z range 25–1000 Da, MS scan accumulation time 0.20 s/spectra, product ion scan accumulation time 0.05 s/spectra. MS/MS is acquired using information dependent acquisition (IDA) with high sensitivity mode selected. The collision energy (CE) was fixed at 35 eV with ± 15 eV. Declustering potential (DP) was set as ± 60 V. IDA was set as follows: Exclude isotopes within 4 Da; Candidate ions to monitor per cycle: 6.
Data preprocessing and statistical analysis
The acquired LC–MS/MS raw data were preprocessed by Compound Discoverer 3.0 (Thermo Fisher Scientific) software, including peak extraction, peak alignment, peak correction, and normalization. A three-dimensional data matrix composed of sample names, peak information (including retention time and molecular weight), and peak areas was output. The structural identification of metabolites was conducted by using accurate mass matching (< 25 ppm) and MS/MS spectral matching, and searching through the self-built database in the laboratory, as well as other online databases such as Bio cyc, HMDB, Metlin, HFMDB, and Lipidmaps.
In the extracted ion features, only the variables having more than 50% of the nonzero measurement values in at least one group were kept. SIMCA-P 14.1 (Umetrics, Umea, Sweden) was used for Orthogonal partial least-squares-discriminant analysis (OPLS-DA). The differential metabolites (DMs) between groups were screened based on a threshold of variable importance on the projection (VIP) values obtained from the OPLS-DA model, where metabolites with VIP > 1.0 and P < 0.05 were considered DMs.
Gene–metabolite network construction
The DGs and DMs were entered into the “Network Analysis” module of the MetaboAnalyst platform to explore the transcriptome–metabolome biological connections. The Cytoscape software was utilized to visualize the “gene–metabolite” network.
Statistical methods
Data management and statistical analyses were performed using GraphPad Prism software (San Diego, CA). The results are presented as Mean (M) ± Standard Deviation (SD). The independent sample t -test or one-way ANOVA was utilized for data analysis. Results with P < 0.05 were considered statistically significant, with P < 0.01 showing a highly significant difference.
Ethical statement
The study was approved by Experimental Ethics Committee at Xiyuan hospital, China Academy of Chinese Medical Sciences (No. 2022XLC045-2), all methods were carried out in accordance with relevant guidelines and regulations. This study was carried out in compliance with the ARRIVE guidelines.
General information and characteristic manifestations of the syndrome
Zero, one, and one deaths were reported in the control, disease, and DS groups, respectively. The NC group animals had a normal diet, free movement, good mental state, and slightly rough hair before sampling. Rats in the disease and DS groups exhibited a significant decrease in activity, reduced food intake, loose and matte hair, decreased body mass, and decreased energy levels. In TCM theory, it is believed that blood stasis and toxin often damage body functions, leading to symptoms such as mental depression and fatigue. The DS group rats showed more significant mental distress, preferring to curl up in a corner with their hair in a ‘burst’ state, and were also less resistant when touched.
Furthermore, after modelling, the DS group animals showed swollen and black purple claw nails, as well as noticeable purple and dark auricular veins and a “black tail” state at the tail. The other rat groups showed no significant changes in characterization (Fig. 2 a). According to the TCM basic theory, the accumulation of blood stasis and toxin in the body can cause poor blood circulation, or even damage the blood vessels, leading to ecchymosis on the surface of the body, local tissue swelling or necrosis. Therefore, based on these manifestations, the DS group exhibited more obvious syndrome characteristics.

( a ) Syndrome characteristics of rats in each group after modeling. ( b ) Neurological score was measured 24 h postoperatively. ** p < 0.01 against the NC group. ( c ) Measurement of the cerebral infarction area (n = 6/group). ** p < 0.01 against the NC group. ( d ) Cerebral infarction area was assessed through TTC staining 24 h post-surgery.
Comparison of neurological deficits and the cerebral infarction areas
We evaluated the degree of neurological deficits in each group of rats 24 h post-surgery. The neurological function scores of the disease model and the DS model groups were significantly higher than those of the NC group ( P < 0.01) (Fig. 2 b). On the other hand, the cerebral infarction area was assessed using TTC staining at 24 h postoperatively. The disease model and DS groups had a significantly greater infarction size than the NC group ( P < 0.01) (Fig. 2 c,d). Furthermore, there was no significant difference between the disease and DS groups (Supplementary Information 1 ).
Comparison of tail blood flow perfusion
The blood perfusion at the tail end of rats usually refers to the blood flow in a specific area of the tail. A state of blood stasis may affect the blood perfusion at the tail of rats, causing it to decrease or be blocked. The number of warm tone pixels was positively correlated with the richness of blood flow per unit area in laser speckle imaging. The tail-end blood flow perfusion of the NC group was abundant compared to that of the DS group, which was significantly lower ( P < 0.01). On the other hand, although the tail-end blood flow perfusion in the disease group exhibited a decreasing trend compared to the control group, there was no statistical significance (Fig. 3 a,b).

( a ) Representative images of tail blood flow perfusion in each rat group. ( b ) Comparison of tail blood flow perfusion in each rat group (n = 7). ** p < 0.01 against the NC group. ## p < 0.01 against the disease group.
Comparison of WBV, PV, and platelet AR
Abnormal changes in blood rheology such as fluidity and viscosity are important pathological mechanisms that progress from blood stasis to the coexistence of blood stasis and toxin. Blood rheology reflects the flow and viscosity of blood, serving as a crucial indicator of the body's blood stasis condition 24 . Compared to the NC group, the WBV at the median shear rate was significantly higher in the disease and DS groups ( P < 0.05, P < 0.01). Notably, the DS group had a significantly higher WBV at the low/median/high shear rate ( P < 0.05, P < 0.01). Consistent with the WBV results, the PV was markedly higher in the disease and DS groups than the NC group ( P < 0.01). Furthermore, the DS group had a significantly higher PV than the disease group ( P < 0.01). Additionally, the maximum and average platelet ARs were significantly higher in the disease and DS model groups than the control group ( P < 0.01). However, there were no significant statistical differences between the disease and DS groups in platelet ARs. These findings show that the DS model rats exhibited more severe blood stasis state. These results are summarized in Tables 1 and 2 .
Comparison of IL-6 expression levels in brain tissue
Whether in the pathogenesis of cerebral infarction or in the formation process of BST syndrome, there will be an increase in inflammatory cytokines. The expression level of IL-6 was significantly higher in the brain tissue of rats in the disease and DS groups compared with the levels in the control group rats ( P < 0.05, P < 0.01). There was no significant differences between the disease and DS groups (Fig. 4 ).

ELISA was used to determine IL-6 expression in ischemic cortical tissue. * p < 0.05, ** p < 0.01 vs . the NC group.
Comparison of HE staining examination
Pathological and morphological changes in brain tissue were observed through HE staining. Neuronal cells in the cortex of the NC group rats were arranged neatly, with normal neuronal morphology (Fig. 5 ). There were no pathological changes such as degeneration or necrosis in the NC group. On the other hand, the disease and DS groups showed noticeable pathological alterations, including disordered cell arrangement, loose structure, common neuronal degeneration and necrosis, nuclear pyknosis, and glial cell proliferation.

Representative images of histopathological changes in the brain tissues in three rat groups captured under a 200× and 400× light microscope.
Transcriptomic characteristics of the IS-BST syndrome
PCA analysis revealed a clear distinction between the three groups along the first principal component with a 59% explained variance (Fig. 6 a). The FPKM density distribution can intuitively reflect the general patterns and characteristics of RNA seq data at the quantitative level. As shown in Fig. 6 b, the FPKM homogeneity was good across individual samples, suggesting that the quality of each sample was good and reliable.

( a ) Principal component analysis: The horizontal axis represents the first principal component, and the vertical axis represents the second principal component; Different colors represent different groups, and different shapes represent different samples. ( b ) FPKM density distribution. N the NC group, M the disease group, C the DS group.
In total, 782 DGs were identified between the disease group and NC groups, with 679 DGs upregulated and 103 DGs downregulated. The heat and volcano maps showed the expression of DGs between Disease group and NC group (Fig. 7 a,b). In addition, 2426 DGs were screened between the DS and NC groups, of which 1361 and 1065 DGs were upregulated and downregulated, respectively. Figure 7 c,d show the heatmap and volcano plot for all DGs, respectively (Supplementary Information 2 , 3 , 5 , 6 ).

( a ) Heat map of DGs between the NC and disease groups. ( b ) Volcano plot of DGs between the NC and disease groups. ( c ) Heat map of DGs between the NC and DS groups. ( d ) Volcano plot of DGs between the NC and DS groups. N the NC group, M the disease group, C the DS group.
Subsequently, the Gene Ontology (GO) function and Kyoto Encyclopedia of Genes and Genomes (KEGG) pathway enrichment analyses were performed on the DGs. The GO analysis comprises Biological Processes (BP), Cellular Components (CC), and Molecular Functions (MF). The top ten significant enrichment terms of BP, CC, and MF with the highest gene counts were visualized in a bar chart. Most of the enriched BP terms of the DGs in the disease model were mainly associated with response to stress, defense response, and inflammatory response. In the CC domain, the DGs of the disease model were mainly involved in the extracellular region, cell periphery, and extracellular space; further, a strong increase in the genes was mainly involved in protein binding, binding, and receptor binding (Fig. 8 a). The DGs of DS model were primarily enriched in regulation of multicellular organismal process, system development, multicellular organism development, and other biological processes; cell periphery, plasma membrane, intrinsic component of plasma membrane, and other cellular components; protein binding, receptor binding, binding, and other molecular functions (Fig. 8 b).

( a ) GO enrichment analysis of the DGs in disease group (red, green, and blue represent the CC, MF, and BP terms, respectively). ( b ) GO enrichment analysis of the DGs in DS group. ( c ) Bubble chart showing the top 20 pathways of DGs between the NC and disease groups. ( d ) Bubble chart showing the top 20 pathways of DGs between the NC and DS groups.
The bubble diagram showed the top 20 significant enrichment potential pathways with the highest gene counts. The results revealed that the DGs of disease group were mainly enriched in complement and coagulation cascades, TNF signaling pathway, NF-kappa B signaling pathway, cytokine-cytokine receptor interaction, etc. (Fig. 8 c). The DGs of DS group were mainly enriched in the TNF signaling pathway, the ECM-receptor interaction pathway, cancer pathways, the lipid and atherosclerosis pathway, and complement and coagulation cascades, among other pathways (Fig. 8 d).
Metabolomic characteristics of the IS-BST syndrome
Herein, 14,623 metabolites were discovered, of which 473 were annotated in the online databases and self-built database in the laboratory. The DMs were generated through OPLS-DA analysis using the SIMCA software, with VIP > 1 and P < 0.05 as the screening conditions. The OPLS-DA score revealed that the NC, disease, and DS groups exhibited a clear trend of separation (Fig. 9 a,b). A total of 102 metabolites were identified between the disease group and NC groups, with 34 DMs upregulated and 68 DMs downregulated. These 102 metabolites are visualized by heat maps and volcano maps (Fig. 9 c,d). Compared with the NC group, 151 metabolites were altered in the DS group, of which 60 and 91 DMs were screened between the two groups and established to be upregulated and downregulated, respectively. Figure 9 e,f show the heatmap and volcano plot for all DGs, respectively (Supplementary Information 4 & 7 ).

( a ) OPLS-DA analysis of three groups: Positive ion mode. ( b ) OPLS-DA analysis of three groups: Negative ion mode. ( c ) Heat map of DGs between the NC and disease groups. ( d ) Volcano plot of DGs between the NC and disease groups. ( e ) Heat map of DGs between the NC and DS groups. ( f ) Volcano plot of DGs between the NC and DS groups. N the NC group, M the disease group, C the DS group.
Key pathways implicated in the disease model and the DS model were identified by metabolic pathway analysis. Several metabolic pathways related to disease group were identified, including central carbon metabolism in cancer, taste transduction, ABC transporters, GABA ergic synapse, and purine metabolism (Fig. 10 a). In addition, several metabolic pathways such as the taste transduction, purine metabolism pathway, central carbon metabolism in cancer, alanine, aspartate, and glutamate matabolism, valine, leucine and isoleucine biosynthesis, and so on were significantly associated with the DS group (Fig. 10 b).

( a ) Bubble chart showing the top 20 pathways of DMs between the NC and disease groups. ( b ) Bubble chart showing the top 20 pathways of DMs between the NC and DS groups.
DGs–DMs interaction analysis
By integrating transcriptomics and metabolomic data, we established a “gene–metabolite” network for the disease model and DS model. As shown in Fig. 11 a and Table 3 , the “gene–metabolite” network of the disease model comprised three mRNAs (C3, F2, and F7) and five metabolites (serotonin, gamma-aminobutyric acid, genistein, estradiol and l-proline). C3 was the most relevant gene with a degree and betweenness of 3 and 12.5, respectively. Estradiol was the metabolite most related to genes, with a degree and betweenness of 2 and 10, respectively.

( a ) The “gene–metabolite” network of the disease model. ( b ) The “gene–metabolite” network of the DS model.
Five mRNAs (F2, C3, F7, C5, and F3) and eight metabolites (serotonin, gamma-aminobutyric acid (GABA), estradiol, l-glutamic acid, l-lysine, genistein, uric acid (UA), and 4-guanidinobutanoic acid) made up the “gene–metabolite” network of the DS model. The most significant metabolite was serotonin, which had degrees and betweennesses of 4 and 25.5, respectively. F2 was the gene most closely associated with metabolites, with betweenness and degree of 6 and 38.67, respectively. Furthermore, F2 was linked to serotonin, l-glutamic acid, 4-guanidinobutanoic acid, l-lysine, GABA, and UA (Fig. 11 b and Table 4 ).
Ischemic Stroke (IS) is a common illness with profound health implications. In recent years, TCM, which has special benefits regarding IS treatment, has received substantial attention. Syndrome differentiation-based treatment is the fundamental principle of TCM in understanding and treating diseases 25 . Currently, the ‘disease-syndrome combination’ is not only a clinical stroke diagnosis and treatment approach, but also a highly consensus research model. The “disease-syndrome combination” animal model is a disease model-based animal model with good reliability and stability. At the same time, the introduction of the ‘syndrome’ concept in TCM has proven to be valuable in reflecting the phased and dynamic changes in disease characterizations in TCM. Specifically, it serves as a platform and conduit for researching clinical diseases in the field of TCM.
Herein, on the basis of our preliminary work, we used a multi-factor combination to construct an animal IS model with blood stasis and toxin syndrome, and explored the biological mechanisms underlying the model through transcriptomic and metabolomic analyses. Our findings hold academic significance as they contribute to the exploration of therapeutic principles underlying TCM formulae and the development of precision medicine for IS treatment.
Multiple evaluation indicators show that the combination of carrageenan and active dry yeast along with MCAO, can be used to successfully establish an IS-BST animal model
Motor dysfunction is one of the main IS manifestations. Herein, rats in both the disease and DS groups showed left limb hemiplegia, with decreased neurological function scores. The cerebral ischemic injury in rats was further confirmed by TTC staining. Compared to the disease model, the DS model included an additional TCM-BST syndrome based on motor dysfunction. The TCM basic theory posits that blood stasis and toxin damage the veins and collaterals, which in turn causes blood to overflow outside the veins and accumulate under the skin, resulting in bruises and ecchymosis on the skin. Therefore, apart from symptoms such as mental distress, decreased activity, reduced food intake, and rough hair, the characteristics of the DS group also included ecchymosis on rats’ ears and claws and thrombi in their tails. Additionally, rats in the DS group also showed a significant decrease in tail blood flow perfusion.
The BST syndrome consists of two syndrome elements: blood stasis and toxin. Pertinent modern studies often interpret blood stasis as abnormal hemorheology, aberrant platelet aggregation function, microcirculation disorders, and so on 26 . Inflammatory responses are often used as a common indicator for evaluating toxins and pathogens 11 . At the same time, thrombosis and inflammatory responses are highly connected mechanisms that promote neuronal damage after ischemia in the complex IS pathological process 27 . Our findings revealed that WBV (low, medium, and high shear), PV, and platelet AR were significantly higher in the DS group than the NC group. It is well-documented that IL-6 is an important inflammatory response marker post-IS 28 . In this study, the IL-6 expression levels in brain tissue were significantly increased in both the disease and DS model groups.
Histopathology can objectively reflect model establishment success and disease severity. Herein, the disease and DS groups showed severe pathological damage, but with no histopathological differences.
Based on the above-mentioned findings, we inferred that the DS group had more stable IS characteristics and the blood stasis and toxin syndrome, implying that it is a preferable standard for constructing an IS-related blood stasis and toxin accumulation animal model (Fig. 12 ).

+ denotes P < 0.05 vs. NC group, ++ denotes P < 0.01 vs. NC group. The DS group presents more severe disease and syndrome characteristics, making it the preferred standard for constructing the IS-BST syndrome model.
Transcriptomic and metabolomic strategies could reveal the biological basis of the IS-BST syndrome
Transcriptomics analysis and metabolomics analysis.
In the transcriptomics study, 782 mRNAs were identified as DGs for the disease. They were mainly enriched in complement and coagulation cascades, TNF signaling pathway, NF-kappa B signaling pathway, cytokine–cytokine receptor interaction, etc. A total of 2426 mRNAs were screened as DGs for the DS model. They were enriched in the TNF signaling pathway, the ECM-receptor interaction pathway, cancer pathways, the lipid and atherosclerosis pathway, and complement and coagulation cascades, etc.
In the enrichment analysis of differential genes between the disease and DS models, the top 20 enriched pathways indicate that atherosclerosis, thrombosis, and inflammatory response are the main relevant pathways. Lipid and atherosclerosis as well as fluid shear stress and atherosclerosis are two of the signal pathways linked to atherosclerosis. Thrombosis-related signaling mechanisms include coagulation cascades and complement. The TNF signaling pathway, NF-kappa B signaling pathway, MAPK signaling pathway, IL-17 signaling pathway, etc. are among the signal pathways linked to the inflammatory response.
In the metabonomics study, 102 metabolites were identified as DMs for the disease. They were enriched in the GABAergic synapse, purine metabolism, protein digestion and absorption, cAMP signaling pathway, etc. A total of 151 metabolites were identified as DMs for the DS model. They were enriched in the alanine, aspartate and glutamate metabolism, valine, leucine and isoleucine biosynthesis, sphingolipid signaling pathway, cAMP signaling pathway, etc. The DS model is established on the basis of the disease model, so there are also some common metabolic pathways between the DS model and the disease model, such as purine metabolism, sphingolipid metabolism, cAMP signaling pathway, and so on.
Gene–metabolite network analysis
Coagulation and complement cascade reaction and the is-bst syndrome.
However, single omics studies are difficult to comprehensively and systematically decipher the regulatory mechanisms of complex pathological processes. Herein, we integrated and analyzed the transcriptomic and metabolomic research findings to construct a “gene–metabolite” network. There are common signatures in the “gene–metabolite” network of the disease and DS models.
Prothrombin (F2), tissue factor (F3), and coagulation factor VII (F7) are the key coagulation elements in the coagulation system. Prothrombin (F2) is a thrombin precursor that exists in an inactive form in the bloodstream. A series of enzyme cascade reactions are triggered when blood vessels are injured, leading to the conversion of F2 into active thrombin. Active thrombin, as a strong activator, then converts fibrinogen into fibrin, promoting blood clot formation 29 . On the other hand, F3 mainly exists on the damaged vascular intima and tissue cells. It binds to F7 in the plasma when tissue damage occurs, triggering a coagulation cascade reaction 30 . Under the synergistic effect of F2, F3, and F7, blood stasis can cause endothelial damage and promote intravascular thrombosis. In this study, the levels of F2 and F7 were significantly elevated in the brain tissues of the disease model and DS model rats, and the levels of F3 were also significantly increased in the brain tissues of the DS model rats. This indicates that the IS-BST rats exhibit stronger coagulation features.
Various components of the complement system and coagulation system interact, activate, and regulate each to synergistically respond to host defense and damage repair. Complement component C3 (C3) is one of the most abundant components in the complement system, which can directly bind to platelets, fibrin, and molecules on the cell surface, thereby promote the coagulation process and thrombosis 31 , 32 . In addition, C3 is also a major participant in the initiation of inflammatory response in the central nervous system diseases 33 , 34 . Inhibiting C3 activity can alleviate the inflammatory response and decrease the volume of cerebral infarction in MCAO mice 35 . A significant increase in serum C3 levels in patients with ischemic stroke has been linked to poor clinical outcomes 36 . C5 is another key component of the complement system, which promotes the migration of neutrophils and monocytes to the injured site and enhances the release of inflammatory factors 37 , 38 . The expression of C5 was also upregulated in the brain after ischemic stroke, and the inhibition of C5 was found to significantly reduce infarct volumes and improve neurological scores 39 . In this study, C3 was significantly upregulated in the brain tissues of the disease model rats, while in the DS model, apart from upregulation of C3, C5 was also significantly upregulated, indicating a more pronounced inflammatory response in the IS-BST.
Although the complement and coagulation system are independent of each other, they closely function together, synergistically participating in key pathways such as thromboinflammatory response 40 , 41 . The “gene–metabolite” regulatory network diagram presented in this study indicates high correlation of these genes, especially in the DS model, suggesting that the biological basis for the interaction between blood stasis and toxin involves the complement and coagulation cascade reactions.
AA metabolism and IS-BST syndrome
In the “gene–metabolite” networks of the two models, there are some common metabolites, including serotonin, estradiol, gamma-aminobutyric acid (GABA), and genistein. Serotonin, also known as 5-hydroxytryptamine, is an indolamine with vasoconstrictive and aggregating properties. Researchers have demonstrated that serotonin can promote the development of platelets and increase procoagulant activity 42 . Researches indicate that acute ischemic stroke patients taking selective serotonin reuptake inhibitors can improve clinical recovery, with mechanisms including stimulating neurogenesis, anti-inflammation, and improving cerebral blood flow 43 , 44 . Estrogen is a lipophilic steroid hormone that exerts its functions by binding to estrogen receptors (ER). Estrogen receptors are present in various tissues, including brain parenchyma 45 . Research indicates that estrogen, especially estradiol, can mitigate brain damage caused by ischemic stroke by regulating immune cell responses 46 . GABA is considered as an inhibitory transmitter that can inhibit neuronal excitation and reduce neuronal damage caused by excitatory glutamate following cerebral ischemia 47 . In this study, serotonin was upregulated in the brain tissues of the disease model rats, while the levels of estradiol and GABA were downregulated.
In this study, l -proline is an unique metabolite in the disease model. A study has shown that five metabolites, including proline, are common in both animal models of ischemic stroke and clinical patients 48 . There may be a certain link between l -proline and ischemic stroke, but the specific mechanism of action still needs further research and exploration.
Studies have indicated that impaired amino acid metabolism is associated with the development of ischemic stroke and BST syndrome 13 , 49 . In the “gene–metabolite” regulatory network of DS model, the differential metabolites are mainly related to amino acid-related metabolism. In addition to serotonin and GABA, l-glutamic acid (Glu), l-lysine, and 4-guanidinobutyric acid also participate in amino acid metabolic pathways. Glu is the most abundant free amino acid in the brain and the main excitatory neurotransmitter in the brain. In cerebral ischemia, glu-mediated excitatory toxicity is an important mechanism leading to the occurrence of neuronal death and brain injury 50 . Lysine is an essential alkaline amino acid that can pass through the blood–brain barrier and provide the necessary energy for the repair and normal functioning of physiological activities of nerve cells. Oral administration of lysine was found to reduce the area of cerebral infarction in rats and alleviate brain edema 51 . 4-Guanidinobutyric acid is a metabolite in the process of converting arginine to GABA, and its reduced content may lead to a decrease in GABA 52 .
In brain tissue samples from the BST group, serotonin and l-glutamic acid were increased, while GABA and l-lysine were decreased. Moreover, the content of 4-Guanidinobutyric acid was observed to increase significantly. Regarding the inconsistent expression trends between 4-Guanidinobutyric acid and GABA, we hypothesized that the conversion of arginine to GABA involves multiple enzymatic reactions and intermediate products, with 4-guanidinobutyric acid being just one of them. Although changes in the content of 4-guanidinobutyric acid may affect the levels of its subsequent metabolites, it is not the sole factor determining the concentration of GABA. Furthermore, more replicated experiments are needed to verify the expression level of 4-guanidinobutyric acid in the brain tissue of DS model rats.
F2 (thrombin)-glutamate and blood stasis—toxin
From the DS model “gene–metabolite” regulatory network, we found that F2 is the core gene with the highest degree of correlation. Thrombin, a serine protease, is encoded by the F2 gene. During cerebral ischemia, thrombin levels are elevated, which positively correlate with the infarct size 53 , 54 . High levels of thrombin has been linked to the occurrence of neurotoxicity 55 . Thrombin can cause blood–brain barrier disruption, increase endothelial permeability and damage to the brain tissue 56 . It has been demonstrated that thrombin stimulates NMDAR potentiation by activating its receptor PAR-1 (protease activator receptor-1), inducing a glutamate-mediated excitotoxicity 57 , 58 . As shown in the “gene–metabolite” network, l-glutamic acid is one of the downstream metabolites of F2. As we mentioned earlier, prolonged blood stasis leads to the production of toxins. To some extent, there is a strong similarity between “F2 (thrombin)–NMDAR/glutamate” pathway and the process of blood stasis brewing poison (Fig. 13 ). Therefore, we we have reasons to believe that the DS model “gene–metabolite” network can not only explain the pathogenesis of the disease, but also elucidate the biological significance of BST syndrome to a certain extent. However, our findings are based on animal research, and hence they may be somewhat different from actual clinical observations. Future research is necessary to validate these findings on IS-BST syndrome clinical patients.

F2 (thrombin)-glutamate and blood stasis—toxin.
Conclusions
In this study, we constructed an animal model of IS-BST syndrome and established a model evaluation system that includes macroscopic characterization, microscopic indicators, and pathological morphology. It can be used to study conditions combining a disease and syndrome. By integrating transcriptomics and metabolomics research results, we found that IS-BST exhibits more prominent characteristics of coagulation and complement cascade reactions, as well as amino acid metabolism disorders. The “F2 (thrombin)-NMDAR/glutamate” pathway we inferred from the “gene–metabolite” regulatory network provides a clear direction for our subsequent pharmacological research. In conclusion, the IS-BST model aligns with TCM theories in understanding diseases and syndromes. It will help promote innovative research on “disease–syndrome therapy formula” and it is expected to provide an effective solution to address the limitations of ischemic stroke treatment.
Data availability
The data in this study are available from the corresponding author upon reasonable request.
Ajoolabady, A. et al. Targeting autophagy in ischemic stroke: From molecular mechanisms to clinical therapeutics. Pharmacol. Ther. 225 , 107848 (2021).
Article CAS PubMed PubMed Central Google Scholar
Mozaffarian, D. et al. Heart disease and stroke statistics-2016 update: A Report From the American Heart Association. Circulation 133 (4), e38-360 (2016).
PubMed Google Scholar
Parvez, S. et al. Dodging blood brain barrier with “nano” warriors: Novel strategy against ischemic stroke. Theranostics 12 (2), 689–719 (2022).
Zhang, S. R., Phan, T. G. & Sobey, C. G. Targeting the immune system for ischemic stroke. Trends Pharmacol. Sci. 42 (2), 96–105 (2021).
Article CAS PubMed Google Scholar
Zhang, L., Zhang, Z. G. & Chopp, M. The neurovascular unit and combination treatment strategies for stroke. Trends Pharmacol. Sci. 33 (8), 415–422 (2012).
Yuan, H. et al. The traditional medicine and modern medicine from natural products. Molecules 21 (5), 559 (2016).
Article PubMed PubMed Central Google Scholar
Wu, B. et al. Meta-analysis of traditional Chinese patent medicine for ischemic stroke. Stroke 38 (6), 1973–1979 (2007).
Article PubMed Google Scholar
Zhang, Y. et al. Efficacy of integrated rehabilitation techniques of traditional Chinese medicine for ischemic stroke: A randomized controlled trial. Am. J. Chin. Med. 41 (5), 971–981 (2013).
Article ADS PubMed Google Scholar
Chen, K. J. The treatment viewpoints and clinical practice of disease identification and syndrome typing. Zhongguo Zhong Xi Yi Jie He Za Zhi 31 (8), 1016–1017 (2011).
Wang, Y. et al. Investigation of invigorating qi and activating blood circulation prescriptions in treating qi deficiency and blood stasis syndrome of ischemic stroke patients: Study protocol for a randomized controlled trial. Front. Pharmacol. 11 , 892 (2020).
Xue, M. et al. Effect of Chinese drugs for activating blood circulation and detoxifying on indices of thrombosis, inflammatory reaction, and tissue damage in a rabbit model of toxin-heat and blood stasis syndrome. Chin. J. Integr. Med. 19 (1), 42–47 (2013).
Wang, J. & Zhang, J. P. A preliminary study of TCM stage-oriented treatment of atherosclerosis. J. Tradit. Chin. Med. 29 (3), 201–204 (2009).
Xu, J. J. et al. Elucidation of the mechanisms and effective substances of paeoniae radix rubra against toxic heat and blood stasis syndrome with a stage-oriented strategy. Front. Pharmacol. 13 , 842839 (2022).
Li, S. et al. Disease-syndrome combination modeling: Metabolomic strategy for the pathogenesis of chronic kidney disease. Sci. Rep. 7 (1), 8830 (2017).
Article ADS PubMed PubMed Central Google Scholar
Yang, H. R. et al. Exploring the fibrin(ogen)olytic, anticoagulant, and antithrombotic activities of natural cysteine protease (ficin) with the κ-carrageenan-induced rat tail thrombosis model. Nutrients 14 (17), 3552 (2022).
Li, Q. et al. NaoXinTong capsule inhibits carrageenan-induced thrombosis in mice. J. Cardiovasc. Pharmacol. 72 (1), 49–59 (2018).
Article MathSciNet CAS PubMed Google Scholar
Liu, Y. et al. Establishment and evaluation of animal models of combined blood stasis and toxin syndrome. Chin. J. Exp. Tradit. Med. Formulae 29 (13), 72–78 (2023).
Google Scholar
Li, W. et al. Multi-omics research strategies in ischemic stroke: A multidimensional perspective. Ageing Res. Rev. 81 , 101730 (2022).
Guo, R. et al. Omics strategies decipher therapeutic discoveries of traditional Chinese medicine against different diseases at multiple layers molecular-level. Pharmacol. Res. 152 , 104627 (2020).
Zhu, X. et al. Multi-omics approaches for in-depth understanding of therapeutic mechanism for Traditional Chinese Medicine. Front. Pharmacol. 13 , 1031051 (2022).
Liu, T. et al. Multi-omics approaches for deciphering the complexity of traditional Chinese medicine syndromes in stroke: A systematic review. Front. Pharmacol. 13 , 980650 (2022).
Longa, E. Z. et al. Reversible middle cerebral artery occlusion without craniectomy in rats. Stroke 20 (1), 84–91 (1989).
Bederson, J. B. et al. Rat middle cerebral artery occlusion: Evaluation of the model and development of a neurologic examination. Stroke 17 (3), 472–476 (1986).
Zhang, Q. et al. UPLC-G2Si-HDMS untargeted metabolomics for identification of Yunnan Baiyao’s metabolic target in promoting blood circulation and removing blood Stasis. Molecules 27 (10), 3208 (2022).
Xu, H. et al. A comprehensive review of integrative pharmacology-based investigation: A paradigm shift in traditional Chinese medicine. Acta Pharm. Sin. B 11 (6), 1379–1399 (2021).
Ma, X. J., Yin, H. J. & Chen, K. J. Research progress of correlation between blood-stasis syndrome and inflammation. Zhongguo Zhong Xi Yi Jie He Za Zhi 27 (7), 669–672 (2007).
De Meyer, S. F. et al. Thromboinflammation in brain ischemia: Recent updates and future perspectives. Stroke 53 (5), 1487–1499 (2022).
Su, J. H. et al. Interleukin-6: A novel target for cardio-cerebrovascular diseases. Front. Pharmacol. 12 , 745061 (2021).
Colucci, G. et al. Venous stasis and thrombin generation. J. Thromb. Haemost. 2 (6), 1008–1009 (2004).
Chi, L. et al. Characterization of a tissue factor/factor VIIa-dependent model of thrombosis in hypercholesterolemic rabbits. J. Thromb. Haemost. 2 (1), 85–92 (2004).
Manderson, A. P. et al. Continual low-level activation of the classical complement pathway. J. Exp. Med. 194 (6), 747–756 (2001).
King, R. J. et al. Fibrinogen interaction with complement C3: A potential therapeutic target to reduce thrombosis risk. Haematologica 106 (6), 1616–1623 (2021).
Zhang, L. Y. et al. Microglia exacerbate white matter injury via complement C3/C3aR pathway after hypoperfusion. Theranostics 10 (1), 74–90 (2020).
Guttikonda, S. R. et al. Fully defined human pluripotent stem cell-derived microglia and tri-culture system model C3 production in Alzheimer’s disease. Nat. Neurosci. 24 (3), 343–354 (2021).
Ma, Y. et al. Significance of complement system in ischemic stroke: A comprehensive review. Aging Dis. 10 (2), 429–462 (2019).
Yang, P. et al. Increased serum complement C3 levels are associated with adverse clinical outcomes after ischemic stroke. Stroke 52 (3), 868–877 (2021).
Escamilla-Rivera, V. et al. Plasma protein adsorption on Fe(3)O(4)-PEG nanoparticles activates the complement system and induces an inflammatory response. Int. J. Nanomedicine 14 , 2055–2067 (2019).
Lu, W. et al. C5a aggravates dysfunction of the articular cartilage and synovial fluid in rats with knee joint immobilization. Mol. Med. Rep. 18 (2), 2110–2116 (2018).
CAS PubMed PubMed Central Google Scholar
Pavlovski, D. et al. Generation of complement component C5a by ischemic neurons promotes neuronal apoptosis. FASEB J. 26 (9), 3680–3690 (2012).
Pryzdial, E. L. G., Leatherdale, A. & Conway, E. M. Coagulation and complement: Key innate defense participants in a seamless web. Front. Immunol. 13 , 918775 (2022).
Pfeiler, S. et al. Propagation of thrombosis by neutrophils and extracellular nucleosome networks. Haematologica 102 (2), 206–213 (2017).
Lopez-Vilchez, I. et al. Serotonin enhances platelet procoagulant properties and their activation induced during platelet tissue factor uptake. Cardiovasc. Res. 84 (2), 309–316 (2009).
Siepmann, T. et al. Selective serotonin reuptake inhibitors to improve outcome in acute ischemic stroke: Possible mechanisms and clinical evidence. Brain Behav. 5 (10), e00373 (2015).
Espinera, A. R. et al. Citalopram enhances neurovascular regeneration and sensorimotor functional recovery after ischemic stroke in mice. Neuroscience 247 , 1–11 (2013).
Yang, M. et al. Dysfunction of estrogen-related receptor alpha-dependent hepatic vldl secretion contributes to sex disparity in Nafld/Nash development. Theranostics 10 (24), 10874–10891 (2020).
Zhong, X. et al. Immunomodulatory role of estrogen in ischemic stroke: Neuroinflammation and effect of sex. Front. Immunol. 14 , 1164258 (2023).
Michalettos, G. & Ruscher, K. Crosstalk between GABAergic neurotransmission and inflammatory cascades in the post-ischemic brain: Relevance for stroke recovery. Front. Cell. Neurosci. 16 , 807911 (2022).
Jia, J. et al. Application of metabolomics to the discovery of biomarkers for ischemic stroke in the murine model: A comparison with the clinical results. Mol. Neurobiol. 58 (12), 6415–6426 (2021).
Chen, X. et al. Effect of Gua Lou Gui Zhi decoction on focal cerebral ischemia-reperfusion injury through regulating the expression of excitatory amino acids and their receptors. Mol. Med. Rep. 10 (1), 248–254 (2014).
Shen, Z. et al. Glutamate excitotoxicity: Potential therapeutic target for ischemic stroke. Biomed. Pharmacother. 151 , 113125 (2022).
Kondoh, T. et al. Lysine and arginine reduce the effects of cerebral ischemic insults and inhibit glutamate-induced neuronal activity in rats. Front. Integr. Neurosci. 4 , 18 (2010).
PubMed PubMed Central Google Scholar
Adkins, D. E. et al. Behavioral metabolomics analysis identifies novel neurochemical signatures in methamphetamine sensitization. Genes Brain Behav. 12 (8), 780–791 (2013).
Chen, B. et al. Thrombin activity associated with neuronal damage during acute focal ischemia. J. Neurosci. 32 (22), 7622–7631 (2012).
Bushi, D. et al. Quantitative detection of thrombin activity in an ischemic stroke model. J. Mol. Neurosci. 51 (3), 844–850 (2013).
Striggow, F. et al. The protease thrombin is an endogenous mediator of hippocampal neuroprotection against ischemia at low concentrations but causes degeneration at high concentrations. Proc. Natl. Acad. Sci. USA 97 (5), 2264–2269 (2000).
Article ADS CAS PubMed PubMed Central Google Scholar
Shavit-Stein, E. et al. Neurocoagulation from a mechanistic point of view in the central nervous system. Semin. Thromb. Hemost. 48 (3), 277–287 (2022).
Becker, D. et al. NMDA-receptor inhibition restores Protease-Activated Receptor 1 (PAR1) mediated alterations in homeostatic synaptic plasticity of denervated mouse dentate granule cells. Neuropharmacology 86 , 212–218 (2014).
Gingrich, M. B. et al. Potentiation of NMDA receptor function by the serine protease thrombin. J. Neurosci. 20 (12), 4582–4595 (2000).
Download references
Acknowledgements
We thank the Shanghai Personal Biotechnology Cp. Ltd (Shanghai, China) for providing omics services. The authors would like to thank all the reviewers who participated in the review, as well as MJEditor ( https://www.mjeditor.com ) for providing English editing services during the preparation of this manuscript.
This research was funded by the Innovation Team and Talents Cultivation Program of National Administration of Traditional Chinese Medicine, grant number ZYYCXTD-C-202007, the China Academy of Chinese Medical Sciences Innovation Fund, grant numbers CI2021A01301 and CI2021A00911, the Scientific and Technological Innovation Project of China Academy of Chinese Medical Sciences, grant number CI2021B006, and the Fundamental Research Funds for the Central public welfare research institutes, grant number 2020YJSZX-3.
Author information
These authors contributed equally: Yue Liu, Wenqiang Cui and Hongxi Liu.
Authors and Affiliations
Xiyuan Hospital, China Academy of Chinese Medical Sciences, Beijing, 100091, China
Yue Liu, Wenqiang Cui, Hongxi Liu, Mingjiang Yao, Wei Shen, Lina Miao, Jingjing Wei, Xiao Liang & Yunling Zhang
Beijing Key Laboratory of Pharmacology of Chinese Materia Region, Institute of Basic Medical Sciences, Xiyuan Hospital of China Academy of Chinese Medical Sciences, Beijing, China
Mingjiang Yao
Department of Neurology, Affiliated Hospital of Shandong University of Traditional Chinese Medicine, Jinan, China
Wenqiang Cui
You can also search for this author in PubMed Google Scholar
Contributions
Study concepts and design: Yunling Zhang, Yue Liu, Mingjiang Yao and Xiao Liang; Investigation, data curation, visualization, writing original draft: Yue Liu; Experimental operations: Yue Liu, Mingjiang Yao, Wenqiang Cui, and Hongxi Liu; Reagents, materials, and analysis tools: Yue Liu and Mingjiang Yao; Review and editing manuscript: Jingjing Wei, Wei Shen, and Lina Miao; Funding acquisition: Xiao Liang and Yunling Zhang. All authors approved the final manuscript after reading.
Corresponding authors
Correspondence to Jingjing Wei , Xiao Liang or Yunling Zhang .
Ethics declarations
Competing interests.
The authors declare no competing interests.
Additional information
Publisher's note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Supplementary information 1., supplementary information 2., supplementary information 3., supplementary information 4., supplementary information 5., supplementary information 6., supplementary information 7., rights and permissions.
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/ .
Reprints and permissions
About this article
Cite this article.
Liu, Y., Cui, W., Liu, H. et al. Exploring the “gene–metabolite” network of ischemic stroke with blood stasis and toxin syndrome by integrated transcriptomics and metabolomics strategy. Sci Rep 14 , 11947 (2024). https://doi.org/10.1038/s41598-024-61633-y
Download citation
Received : 01 January 2024
Accepted : 08 May 2024
Published : 25 May 2024
DOI : https://doi.org/10.1038/s41598-024-61633-y
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Ischemic stroke
- Blood stasis and toxin
- Traditional Chinese Medicine
- Transcriptomics
- Metabolomics
By submitting a comment you agree to abide by our Terms and Community Guidelines . If you find something abusive or that does not comply with our terms or guidelines please flag it as inappropriate.
Quick links
- Explore articles by subject
- Guide to authors
- Editorial policies
Sign up for the Nature Briefing newsletter — what matters in science, free to your inbox daily.

- Tools and Resources
- Customer Services
- Affective Science
- Biological Foundations of Psychology
- Clinical Psychology: Disorders and Therapies
- Cognitive Psychology/Neuroscience
- Developmental Psychology
- Educational/School Psychology
- Forensic Psychology
- Health Psychology
- History and Systems of Psychology
- Individual Differences
- Methods and Approaches in Psychology
- Neuropsychology
- Organizational and Institutional Psychology
- Personality
- Psychology and Other Disciplines
- Social Psychology
- Sports Psychology
- Back to results
- Share This Facebook LinkedIn Twitter
Article contents
Empathy and altruism.
- Eric L. Stocks Eric L. Stocks Department of Psychology and Counseling, University of Texas at Tyler
- and David A. Lishner David A. Lishner University of Wisconsin Oshkosh
- https://doi.org/10.1093/acrefore/9780190236557.013.272
- Published online: 24 October 2018
The term empathy has been used as a label for a broad range of phenomena, including feeling what another person is feeling, understanding another person’s point of view, and imagining oneself in another person’s situation. However, perhaps the most widely researched phenomenon that goes by this label involves an other-oriented emotional state that is congruent with the perceived welfare of another person. The feelings associated with empathy include sympathy, tenderness, and warmth toward the other person. Other variations of empathic emotions have been investigated too, including empathic joy, empathic embarrassment, and empathic anger. The term altruism has also been used as a label for a broad range of phenomena, including any type of helping behavior, personality traits associated with helpful persons, and biological influences that spur protection of genetically related others. However, a particularly fruitful research tradition has focused on altruism as a motivational state with the ultimate goal of protecting or promoting the welfare of a valued other. For example, the empathy–altruism hypothesis claims that empathy (construed as an other-oriented emotional state) evokes altruism (construed as a motivational state). Empathy and altruism, regardless of how they are construed, have important consequences for understanding human behavior in general, and for understanding social relationships and well-being in particular.
- vicarious emotions
- perspective taking
- prosocial behavior
- social motivation
You do not currently have access to this article
Please login to access the full content.
Access to the full content requires a subscription
Printed from Oxford Research Encyclopedias, Psychology. Under the terms of the licence agreement, an individual user may print out a single article for personal use (for details see Privacy Policy and Legal Notice).
date: 27 May 2024
- Cookie Policy
- Privacy Policy
- Legal Notice
- Accessibility
- [66.249.64.20|185.80.151.41]
- 185.80.151.41
Character limit 500 /500
- Search Menu
- Sign in through your institution
- Advance articles
- Author Interviews
- Research Curations
- Author Guidelines
- Open Access
- Submission Site
- Why Submit?
- About Journal of Consumer Research
- Editorial Board
- Advertising and Corporate Services
- Self-Archiving Policy
- Dispatch Dates
- Journals on Oxford Academic
- Books on Oxford Academic
Are ‘10-Grams of Protein” Better than ’Ten Grams of Protein”? How Digits versus Number Words Influence Consumer Judgments
- Article contents
- Figures & tables
- Supplementary Data
Marisabel Romero, Adam W Craig, Milica Mormann, Anand Kumar, Are ‘10-Grams of Protein” Better than ’Ten Grams of Protein”? How Digits versus Number Words Influence Consumer Judgments, Journal of Consumer Research , 2024;, ucae030, https://doi.org/10.1093/jcr/ucae030
- Permissions Icon Permissions
Numerical information can be communicated using different number formats, such as digits (“5”) or number words (“five”). For example, a battery product may claim to last for “5 hours” or “five hours.” And while these two formats are used interchangeably in the marketplace, it is not clear how they influence consumer judgments and behavior. Via six experimental studies, two online ad campaigns, and one large secondary dataset analysis, we find that digits, compared to number words, positively affect consumer behavior. We refer to this phenomenon as the number format effect . We further show that the number format effect occurs because consumers feel that digits (vs. number words) are the right way to present numerical information: digits lead to a sense of feeling right that then affects consumer behavior. Finally, we show that the number format effect is amplified when credibility of the source of information is low, and attenuated when source credibility is high. The current research advances knowledge of how numerical information influences consumer judgments and behavior and carries important implications for marketers and policymakers as they communicate numerical information to consumers.
Email alerts
Citing articles via.
- Recommend to your Library
Affiliations
- Online ISSN 1537-5277
- Print ISSN 0093-5301
- Copyright © 2024 Journal of Consumer Research Inc.
- About Oxford Academic
- Publish journals with us
- University press partners
- What we publish
- New features
- Open access
- Institutional account management
- Rights and permissions
- Get help with access
- Accessibility
- Advertising
- Media enquiries
- Oxford University Press
- Oxford Languages
- University of Oxford
Oxford University Press is a department of the University of Oxford. It furthers the University's objective of excellence in research, scholarship, and education by publishing worldwide
- Copyright © 2024 Oxford University Press
- Cookie settings
- Cookie policy
- Privacy policy
- Legal notice
This Feature Is Available To Subscribers Only
Sign In or Create an Account
This PDF is available to Subscribers Only
For full access to this pdf, sign in to an existing account, or purchase an annual subscription.
IMAGES
VIDEO
COMMENTS
Step 2: Methods. Next, indicate the research methods that you used to answer your question. This part should be a straightforward description of what you did in one or two sentences. It is usually written in the past simple tense, as it refers to completed actions.
Definition and Purpose of Abstracts An abstract is a short summary of your (published or unpublished) research paper, usually about a paragraph (c. 6-7 sentences, 150-250 words) long. A well-written abstract serves multiple purposes: an abstract lets readers get the gist or essence of your paper or article quickly, in order to decide whether to….
You can, however, write a draft at the beginning of your research and add in any gaps later. If you find abstract writing a herculean task, here are the few tips to help you with it: 1. Always develop a framework to support your abstract. Before writing, ensure you create a clear outline for your abstract.
5. How to Format an Abstract. Most abstracts use the same formatting rules, which help the reader identify the abstract so they know where to look for it. Here's a list of formatting guidelines for writing an abstract: Stick to one paragraph. Use block formatting with no indentation at the beginning.
The abstract is your chance to let your readers know what they can expect from your article. Learn how to write a clear, and concise abstract that will keep your audience reading. How your abstract impacts editorial evaluation and future readership. After the title, the abstract is the second-most-read part of your article. A good abstract can ...
Authors abstract various longer works, including book proposals, dissertations, and online journal articles. There are two main types of abstracts: descriptive and informative. A descriptive abstract briefly describes the longer work, while an informative abstract presents all the main arguments and important results.
Research Paper Abstract Examples could be following: Example 1: Title: "The Effectiveness of Cognitive-Behavioral Therapy for Treating Anxiety Disorders: A Meta-Analysis". Abstract: This meta-analysis examines the effectiveness of cognitive-behavioral therapy (CBT) in treating anxiety disorders. Through the analysis of 20 randomized ...
How to Write an Abstract | Steps & Examples. Published on 1 March 2019 by Shona McCombes.Revised on 10 October 2022 by Eoghan Ryan. An abstract is a short summary of a longer work (such as a dissertation or research paper).The abstract concisely reports the aims and outcomes of your research, so that readers know exactly what your paper is about.
Developing such a skill takes practice. Here is an exercise to help you develop this skill. Pick a scientific article in your field. Read the paper with the abstract covered. Then try to write an abstract based on your reading. Compare your abstract to the author's. Repeat until you feel confident.
Include 5 to 10 important words or short phrases central to your research in both the abstract and the keywords section. For example, if you are writing a paper on the prevalence of obesity among lower classes that crosses international boundaries, you should include terms like "obesity," "prevalence," "international," "lower ...
Rather, the descriptive abstract just tells the reader what the research or the article is about and not much more. The descriptive abstract is more of a tagline or a teaser, whereas the informative abstract is more like a summary. You will find both types of abstracts in the examples below. Abstract Examples Informative Abstract Example 1
Keywords: along with the abstract, specific words and phrases related to the topics discussed in the research should be added. These words are usually around five, but the number can vary depending on the journal's guidelines. Abstract example. This abstract, taken from ScienceDirect, illustrates the ideal structure of an abstract. It has 155 ...
An abstract summarizes, usually in one paragraph of 300 words or less, the major aspects of the entire paper in a prescribed sequence that includes: 1) the overall purpose of the study and the research problem(s) you investigated; 2) the basic design of the study; 3) major findings or trends found as a result of your analysis; and, 4) a brief summary of your interpretations and conclusions.
The value of your abstract. Although the abstract is one of the last elements of a article to be written, it is one of the first elements that will be read. Reviewers only see the title and abstract of an article before they decide to review it or not. The reader will decide whether the rest of your article is interesting to them while they are ...
Abstracts are usually a student's first point of contact with professional scientific research. Although reading a whole article can be daunting, reading an abstract is much simpler and the benefits to your learning are ... Analyze a Sample Abstract Abstracts follow the same order as the article: introduction, Method, Results, and Discussion ...
Set a 1-inch (2.54 centimeter) margin on all sides. The running head should be aligned to the left at the top of the page. The abstract should be on the second page of the paper (the first one is reserved for the title). Avoid indentations, unless you must include a keywords section at the end of the abstract.
An APA abstract is a brief, comprehensive summary of the contents of an article, research paper, dissertation, or report. It is written in accordance with the guidelines of the American Psychological Association (APA), which is a widely used format in social and behavioral sciences.
1. Descriptive. This abstract in research paper is usually short (50-100 words). These abstracts have common sections, such as -. Background. Purpose. Focus of research. Overview of the study. This type of research does not include detailed presentation of results and only mention results through a phrase without contributing numerical or ...
INTRODUCTION. This paper is the third in a series on manuscript writing skills, published in the Indian Journal of Psychiatry.Earlier articles offered suggestions on how to write a good case report,[] and how to read, write, or review a paper on randomized controlled trials.[2,3] The present paper examines how authors may write a good abstract when preparing their manuscript for a scientific ...
There are six steps to writing a standard abstract. (1) Begin with a broad statement about your topic. Then, (2) state the problem or knowledge gap related to this topic that your study explores. After that, (3) describe what specific aspect of this problem you investigated, and (4) briefly explain how you went about doing this.
Methods - The methods section should contain enough information to enable the reader to understand what was done, and how. It should include brief details of the research design, sample size, duration of study, and so on. Results - The results section is the most important part of the abstract. This is because readers who skim an abstract do so ...
Abstracts. Abstracts provide a summary and preview of an academic work, such an article, research proposal, or conference presentation. Abstracts are the first part of an article that readers will see: They set expectations and help readers understand what will come next. All abstracts used in this handout are from published articles from ...
For example, research on new plant compounds associated with herbal medicine ... Our use of titles/abstracts from the top 17 plant science journals as positive examples allowed us to identify papers we typically see in these journals, but this may have led to us missing "outlier" articles, which may be the most exciting. Another limitation ...
Using a sample of 39 countries representing 88% of global GDP, we find that real economic uncertainty (REU) has negative long-lasting domestic economic effects and transmits across countries. The international spillover effects of REU are both statistically significant and economically meaningful, and trade ties play a key role in explaining ...
Abstract. Social media has changed the industry in a variety of aspects. Since we are living in the modern day, social media and the internet have a significant impact on how customers interact ...
A research model combining a disease and syndrome can provide new ideas for the treatment of ischemic stroke. In the field of traditional Chinese medicine, blood stasis and toxin (BST) syndrome is ...
However, a particularly fruitful research tradition has focused on altruism as a motivational state with the ultimate goal of protecting or promoting the welfare of a valued other. For example, the empathy-altruism hypothesis claims that empathy (construed as an other-oriented emotional state) evokes altruism (construed as a motivational state).
Abstract. Numerical information can be communicated using different number formats, such as digits ("5") or number words ("five"). For example, a battery product may claim to last for "5 hours" or "five hours."
Surface vaporization of metals is currently receiving significant attention as a wastewater treatment technique. This article examined the wettability transition of a treated titanium surface (so-called an evaporator) under varied storage conditions. Several aspects of the transition mechanism were evaluated, including contact angles, surface chemistry, and wetting dynamics. The titanium ...